SAFIRE
SAFIRE: Segment Any Forged Image Region
Myung-Joon Kwon1* , Wonjun Lee1* , Seung-Hun Nam2 , Minji Son1 , Changick Kim1
1韩国科学技术院(KAIST)电气工程学院
2NAVER WEBTOON
AI,韩国Seongnam
摘要
大多数技术将图像伪造定位问题视为二值分割任务,训练神经网络将原始区域标记为0,伪造区域标记为1。相比之下,我们从更基础的角度出发,根据图像的来源对其进行划分。为此,我们提出了“任意伪造图像区域分割”(SAFIRE),通过点提示解决伪造定位问题。图像上的每个点用于分割包含自身的源区域。这使得我们可以将图像划分为多个源区域,这是首次实现的功能。此外,SAFIRE不是记忆特定的伪造痕迹,而是自然地关注每个源区域内的一致特征。这种方法导致了更稳定和有效的学习,在新任务和传统的二值伪造定位中均表现出色。
Code: https://github.com/mjkwon2021/SAFIRE
1. 引言
在人工智能(AI)时代,图像编辑软件(Fu等人,2023;Yu等人,2023)和复杂的生成模型(Rombach等人,2022;Ho、Jain和Abbeel,2020)的普及使得图像伪造比以往任何时候都更容易被发现,同时也更加难以检测(Lin等人,2024)。图像操作的便捷性对视觉信息完整性至关重要的领域产生了重大影响,包括新闻业中假新闻的传播、执法部门使用伪造证据以及生物医学研究中虚假显微图像的存在(Verdoliva,2020;Sabir等人,2021)。因此,在图像中检测并精确定位伪造内容对于维护数字媒体的信任至关重要。
目前,大多数图像取证方法通过二值分割来解决图像伪造定位(IFL)问题(Guillaro等,2023;Kwon等,2022;Liu等,2022;Dong等,2022;Hu等,2020;Wu等,2022;Zhou等,2023a;Ji等,2023a;Sun等,2023)。也就是说,在图像中,未被相机捕捉到的区域标记为0,而被篡改过的区域标记为1,以训练深度神经网络。
相反,我们从一个更基本的角度来看待IFL,即根据图像的起源将其划分为不同的区域。在此背景下,我们将这些不同的区域定义为源区域,即独立捕获、AI生成或处理的图像的不同部分(图1)。
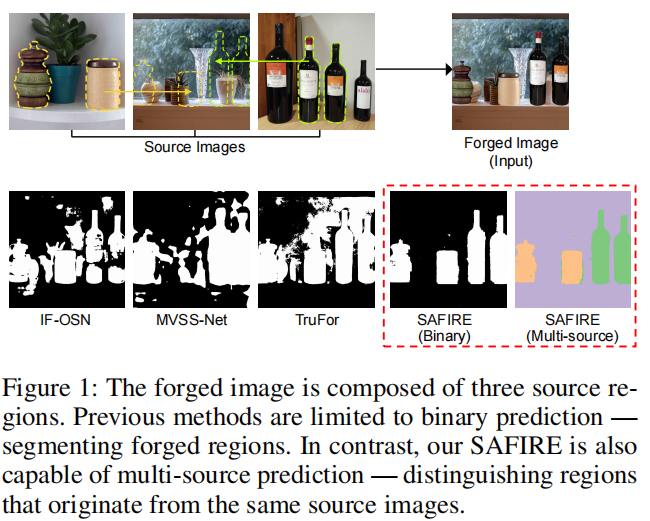
图1:伪造图像由三个源区域组成。以往的方法仅限于二值预测——分割伪造区域。相比之下,我们的SAFIRE还能够进行多源预测——区分来自同一源图像的区域。
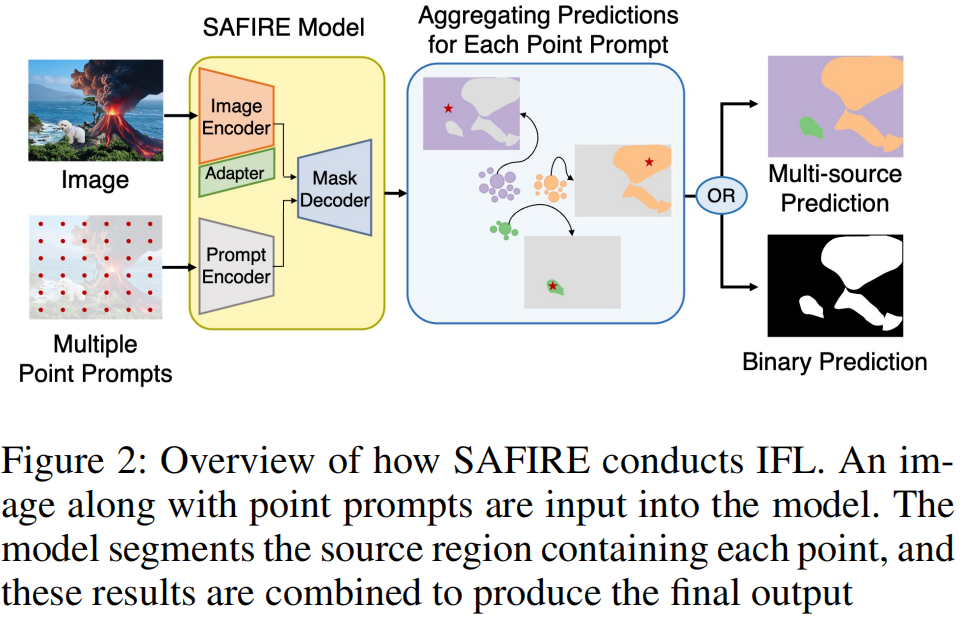
从这个角度来看,我们提出了“任意伪造图像区域分割”(SAFIRE),一种基于点提示的新颖IFL方法,旨在根据图像的原始来源精确地将其分割成区域。SAFIRE采用点提示技术,其中图像上的每个点都会分割出与之共享同一来源的区域(图2)。
为了实现这一目标,我们利用了“Segment Anything
Model”(SAM)(Kirillov等人,2023年)的点提示功能,并对其进行了几处改进。首先,SAFIRE会分割包含给定点的源区域,而SAM则会分割该点周围的所有有意义的部分。其次,虽然SAM处理的是模糊的真实情况,但SAFIRE有明确的真实情况,即一个源区域内所有点的答案都相同。第三,SAFIRE内部生成并使用点提示,因此无需手动输入来指定点。
SAFIRE框架由预训练、训练和推理三个阶段组成。在预训练阶段,基于源区域的对比学习被应用于增强图像编码器的特征提取能力。在训练阶段,模型被训练以分割与给定点提示相对应的源区域。尽管该模型可以使用仅包含二元标签的伪造数据集进行训练,但它能够进行多源预测。在推理阶段,点网格生成多个掩码,然后将这些掩码组合起来,产生最终的源分区结果。
SAFIRE是首个能够区分图像被篡改两次或更多次时的每个来源的方法,从而产生三个或更多的来源。区分每个来源比仅仅定位篡改像素能更好地解释被操纵的图像。此外,它还促进了后续分析,例如来源过滤,这涉及从一组候选图像中检索每个源区域的原始图像(Pinto等,2017;Moreira等,2018;Verdoliva,2020)。因此,在现实场景中,当多次操作很常见时,多源分区对图像取证特别有益。
此外,新颖的提示机制使SAFIRE能够通过考虑真实区域和篡改区域的可互换性来有效学习,这一特性在IFL中我们称之为标签不可知性。篡改区域通常缺乏共同的痕迹,与真实区域相比,它们只是图像中的不同来源(Huh等人,2018)。因此,试图记忆伪造痕迹会导致混淆,从而导致学习不稳定。相反,SAFIRE使用点作为参考来学习每个源区域的均匀特征,而不是记忆伪造痕迹。这种方法导致了稳定且有效的学习,在传统的二值IFL和新的源分区任务中均取得了高性能。
作为第一篇通过多源分割解决IFL问题的论文,我们创建了一个由多源图像组成的SafireMS数据集,以促进该领域的进一步研究。我们计划公开发布。
我们的主要贡献可以总结如下:
- 我们引入了一种新的IFL任务,该任务将伪造的图像按每个来源进行划分。它有助于理解伪造图像的组成,并使进一步的分析更容易。
- 我们提出了一种新的IFL方法SAFIRE,它使用内部的点提示。它是第一个能够进行多源分区的技术,但它可以使用传统的二进制数据集进行训练。
- 大量的实验表明,SAFIRE在传统的二进制IFL和新任务中都表现出最佳性能。
- 为了便于对新任务的研究,我们构建并发布了一个包含由多个来源组成的图像的伪造数据集。
2. 相关工作
图像伪造定位
Segment Anything Model
IFL中的SAM
最近,有人尝试在IFL技术中使用SAM。一种方法(Su、Tan和Huang 2024)通过向SAM添加SRM滤波器(Zhou等2018)构建了IFL模型。这种方法完全去除了提示编码器,实际上将SAM用作现代分割主干。另一项研究(Karageorgiou、Kordopatis-Zilos和Papadopoulos 2024)利用注意力机制融合各种信号,并为此使用预训练且冻结的SAM进行实例分割。
总之,以往的研究主要将SAM用作骨架或仅用于获取分割掩模。这些方法忽视了SAM最重要的特性——其可提示能力,未能充分发挥其潜力。同时,我们开创性地将可提示的分割模型应用于图像的源区域划分。通过使用基于SAM的点提示,我们使每个点都能作为参考,分割包含该点的源区域。此外,受SAM自动掩模生成过程的启发,我们提出了一种推理技术,该技术涉及以网格模式在图像上放置点并汇总结果。这种方法首次实现了多源划分。
3. 方法
3.1 概观
我们提出的核心方法,即SAFIRE框架,涵盖了IFL的预训练、训练和推理过程。该框架中使用的神经网络称为SAFIRE模型,无需特定结构,可以自由修改。本文中,我们采用了SAM的略微修改结构,在图像编码器中仅添加适配层,以增强模型通过利用低级信号提取取证特征的能力(详见图2及附录)。该模型由图像编码器E(·)、提示编码器F(·)和掩码解码器D(·,·)组成。模型以图像I和点提示P作为输入,输出包含该点的源区域的预测图X和置信度分数s。
接下来的章节将深入详细解释SAFIRE框架。首先,为了有效进行源图像分割,通过区域到区域对比学习对图像编码器进行预训练。随后,在主要的训练阶段,模型使用点提示对源区域进行分割进行训练,在最终的推理阶段,以网格的形式将多个点输入到模型中,并将所有结果聚合以获得最终的预测热图。
3.2 预训练:区域对区域对比学习
我们提出区域到区域对比学习,以预训练图像编码器,实现有效的源区域划分(图3)。
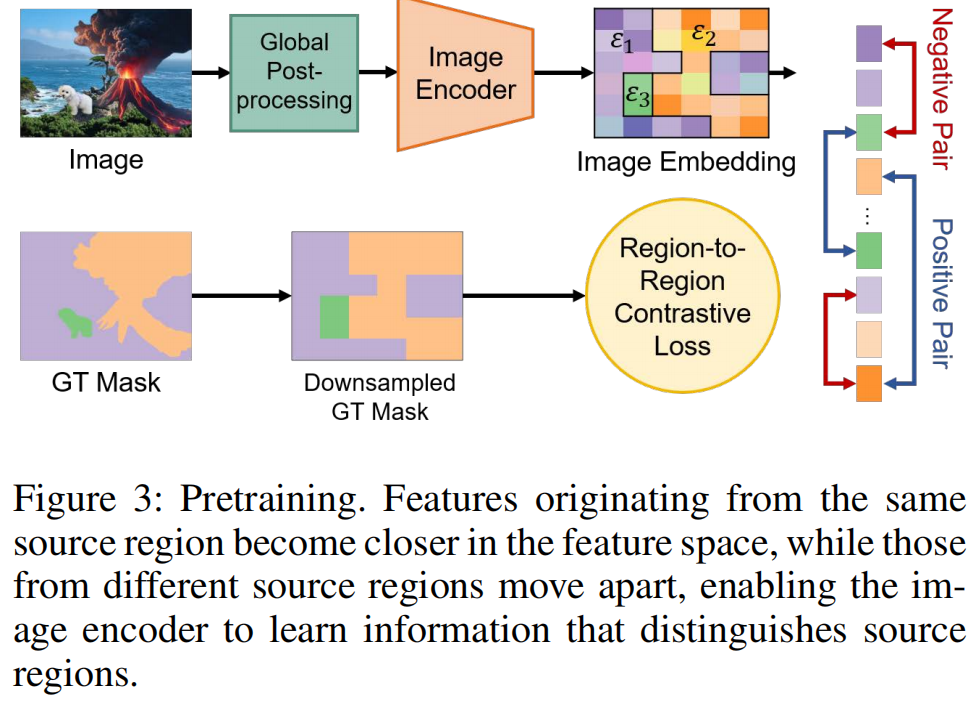
该方法旨在使来自同一源区域的嵌入在特征空间中靠近,而不同源区域的嵌入则相距较远,当一张图像包含两个或多个源时。
利用对比学习中InfoNCE损失的经验证明的有效性(Oord,Li和Vinyals
2018),我们定义我们的损失函数如下。设\(I\in\mathbb{R}^{3\times H\times
W}\)是由r个源组成的输入图像,\(E(\cdot)\)为图像编码器,\({\mathcal{E}}=E(I)\in\mathbb{R}^{V\times{\frac{H}{K}}\times{\frac{W}{K}}}\)为图像嵌入,下采样比为K。我们稍微滥用一下符号,把\({\mathcal{E}}\)看作是V维图像嵌入的集合。然后在\({\mathcal{E}}\)中存在\(\frac{H}{K}\times{\frac{W}{K}}\)个嵌入\(q\in\mathbb{R}^{V}\)。我们还令\(\{\mathcal{E}_{i}\}_{i=1}^{r}\)是\({\mathcal{E}}\)的划分,其对应于I中的源区域。
然后,我们定义区域到区域对比损失\(\mathcal{L}_{R2R}\)为: \[I n f o N C
E(q,p,N)=-\log\left({\frac{\exp\left({\frac{q\cdot
p}{\pi}}\right)}{\exp\left({\frac{q\cdot p}{\tau}}\right)+\sum_{n\in
N}\exp\left({\frac{q\cdot n}{\tau}}\right)}}\right),\]
\[\mathcal{L}_{R2R}=\frac{1}{|\varepsilon|}\sum_{i=1}^{r}\sum_{q\in\varepsilon_{i}}I n f o N C E\Big(q,\overline{\varepsilon_{i}\textbackslash\{q\}},\varepsilon\textbackslash\varepsilon_i\Big)\]
其中,τ是一个称为温度的超参数,|·|返回元素的数量,\(\overline{\cdot}\)返回所有元素的平均值。
在图像通过图像编码器之前,各种模糊、噪声添加或对比度变化等全局后处理被概率性地应用到图像上。通过这样做,我们期望图像编码器对全局常见变化具有鲁棒性,并更多地关注细微的局部差异。
考虑到图像编码器的体积较大,我们确定目前可用的公开伪造数据集在规模和噪声方面都不够充分。因此,我们生成并使用了一个大规模无噪声的数据集SafireMS-Auto。更多内容见附录。
3.2 训练:使用点提示进行源区域分割
完成图像编码器预训练后,SAFIRE模型将进行主要训练,以根据指定的点提示准确分割源区域(图4)。
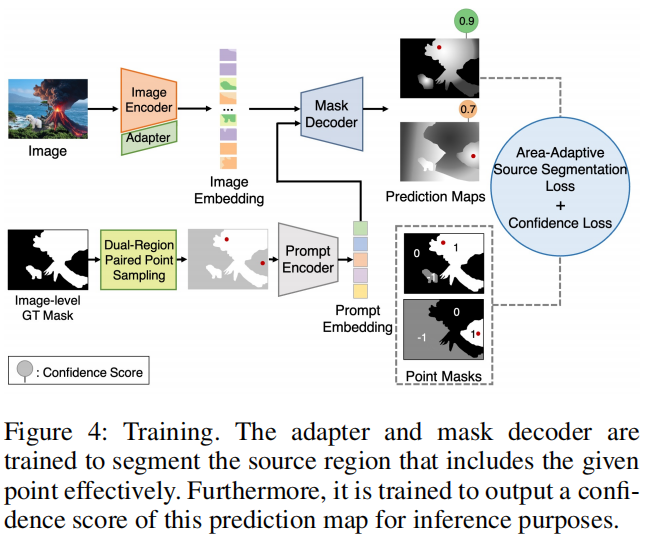
图像编码器和提示编码器均被冻结:图像编码器处于预训练状态,提示编码器则保持原始SAM状态。通过向掩码解码器输入图像嵌入和提示嵌入,训练适配组件和掩码解码器,确保输出与正确的掩码对齐。
3.2.1 创建点遮罩
在训练过程中,需要将图像级别的真实掩模转换为对应给定点的掩模,我们称之为点掩模。如果存在多源掩模,每个源区域分配不同的标签,则可以通过将包含该点的源区域赋值为1,其他区域赋值为0来简单创建点掩模。然而,目前几乎所有用于IFL任务的数据集都仅以二进制形式存在,将被篡改的部分标记为1,未改变的部分标记为0。
我们介绍了一种方法,将这些图像级别的二值掩码转换为点掩码。如果一张处理过的图像仅使用两个来源,标记为0和1的区域各自代表一个单一的源区域。进一步地,我们还考虑了连通组件。包含给定点的连通区域被标记为1,而与该区域相邻的其他连通区域则被标记为0。不相邻的区域被赋予-1的忽略标签,在计算损失时忽略这些标签。这种转换使我们能够仅使用带有二值标签的数据集进行多源分区训练。
具体来说,设\(Y\in\{0,1\}^{H\times
W}\)是图像I的真实掩码,其中包含c个连通分量,\(R=\{(i,j)\in\mathbb{Z}^{2}:0\leq i\lt H,0\leq j\lt
W\}\)是I的整数坐标集,\(\{R_{i}\}_{i=1}^{c}\)是覆盖Y连通分量的R的划分,\(P\in R\)是一个点提示,\(R^P\)是包含P的区域,P属于\(\{R_{i}\}_{i=1}^{c}\)。然后,点掩模\(Y_{P}\in\{-1,0,1\}^{H\times
W}\)可以计算为: \[Y_{P}[i,j]=\begin{cases}\begin{aligned}1,\qquad&
\mathrm{if}\ (i,j)\in R^{P}\\0,\qquad& \mathrm{if}\ (i,j)\in
neighbors(R^{P})\\-1,\qquad&
\mathrm{otherwise}\end{aligned}\end{cases}\]
其中,neighbors(·)返回相邻区域的并集。
3.2.2 双区域配对点采样
图像编码器独立于点提示计算图像嵌入。充分利用这一特性,可以通过同时处理单个图像的多个点提示来实现高效训练。此外,为了平衡源区域,根据图像级别的真实标注,始终从标记为0和1的区域中成对采样点。
3.2.3 区域自适应源分割损失
对于每个点,我们可以定义一个损失函数,该函数最小化预测图与点掩模之间的差异(图4)。这里,并非所有点掩模内的像素都对损失有同等贡献,因为这样做会导致较小区域被忽略。传统的IFL技术通过赋予篡改类别更大的权重来解决大多数图像中篡改区域较小的问题(Kwon等,2022)。然而,在我们的点掩模中,没有区分篡改区域和原始区域;只有多个源区域存在。因此,我们采用一种策略,即无论这些区域中的正确标签是0还是1,都赋予每个点掩模内较小区域更大的权重。这与大多数语义分割任务中使用的特定类别权重不同,后者是在单个图像内计算权重(Wang等,2020)。
设I为输入图像,P为点提示,\((X, s)=D(E(I),
F(P))\)为掩码解码器的输出,其中X是预测图,s是置信度分数,\(Y_P\)为P的真实点掩码。我们仅在有效标签区域\(R^{Y_{P},\{0,1\}}\)内计算损失,通过\(R^{A,B}=\left\{(i,j)\in R\;:\;A[i,j]\in
B\right\}\)来实现。然后区域自适应源分割损失\(\mathcal{L}_{AASS}\)定义为: \[\mathcal{L}_{A A S
S}=-\operatorname*{\mathbb{E}}_{(i,j)}[w_{1}\cdot
Y[i,\,j]\cdot\log(\sigma(X[i,\,j]))+\,w_{0}\cdot(1-Y[i,j])\cdot\log(1-\sigma(X[i,j]))]\\w_{1}=\operatorname*{min}\left(\frac{|R^{Y_P,\{0,1\}}|}{|R^{Y_P,\{1\}}|},C_{A
A S
S}\right){\mathrm{~,~and~}}w_{0}=\operatorname*{min}\left(\frac{|R^{Y_P,\{0,1\}}|}{|R^{Y_P,\{0\}}|},C_{A
A S S}\right)\] 其中期望是在\(R^{Y_P,\{0,1\}}\)上计算的,σ(·)是一个S型函数,\(C_{AASS}\)是一个限制权重的超参数。
3.2.3 置信度损失
用于推理时,掩码解码器还预测置信度分数。与SAM不同的是,SAM预测的是框级平均交并比(mIoU)分数,而我们的模型预测像素精度来衡量整体性能,而不是矩形mIoU。置信度分数损失\(\mathcal{L}_{c o n f}\)定义为: \[\mathcal{L}_{c o n f}=\operatorname*{MSE}_{R^{Y_{P},\{0,1\}}}(a c c\,(b i n(X),Y_{P}),s)\] 其中,bin(·)将输入阈值化为二进制映射,将大于0的值转换为1,小于或等于0的值转换为0,MSE(·,·)返回像素均方误差,acc(·)返回准确度。
3.2.4 总训练损失
最后,我们得到总训练损失Ltrain如下: \[\mathcal{L}_{t r a i n}=\mathcal{L}_{A A S S}+\lambda_{c o n f}\cdot L_{c o n f},\] 其中λconf是一个平衡两种损失的超参数。
3.3 推理:多点聚合
推理使用多个点提示(图5)。
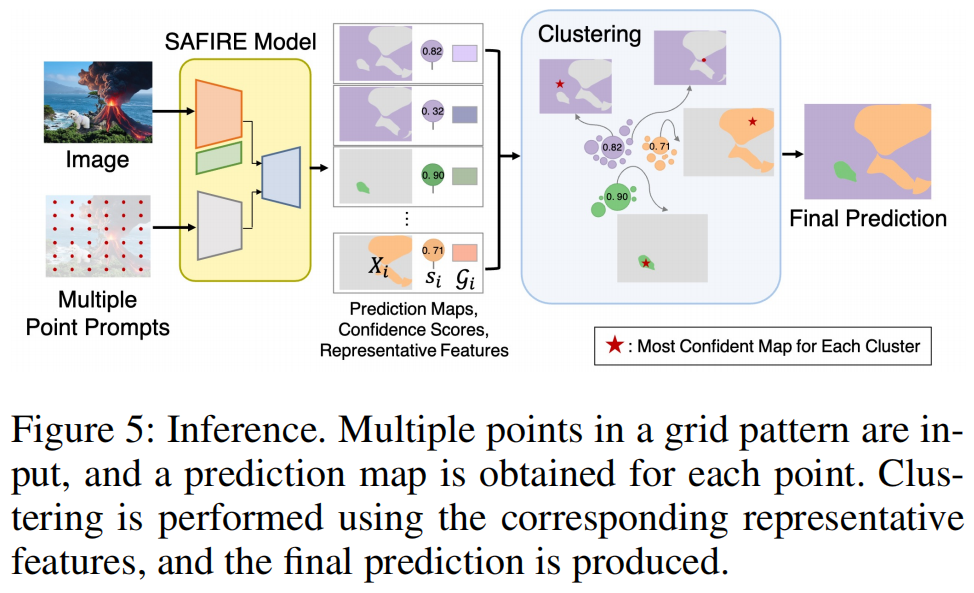
除了要推断的图像外,还以网格格式(例如16×16)提供点作为模型的输入。输出掩码被聚合以获得最终预测,这可以是多源地图或二值地图。
设I为输入图像,P1,···,PN为提示点。首先,我们计算图像嵌入E
= E(I)和所有i的提示点嵌入Fi =
F(Pi)。由于图像嵌入提取与提示点无关,因此每张图像只需执行一次。因此,即使使用多个提示点,总计算量也不会大幅增加。
之后,图像嵌入和点嵌入通过掩码解码器,从而可以得到对应于每个点的预测。掩码解码器的输出D(·,·)可以表示为:
\[(\{X_{1},\cdot\cdot\cdot\,,X_{N}\},\{s_{1},\cdot\cdot\cdot\,,s_{N}\})=D({\mathcal{E}},\{\mathcal{F}_{1},\cdot\cdot\cdot\,,\mathcal{F}_{N}\}),\]
其中Xi是一个预测图,si是Xi的一个置信度分数。
下一步是计算每个预测Xi的代表性特征,这是对应于预测区域的图像嵌入的平均值。我们定义一个函数\(g:\mathbb{R}^{H\times
W}\rightarrow\mathbb{R}^{V}\),如下所示: \[g(X)=\frac{1}{\left|\mathcal{R}^{b i
n(x),\{1\}}\right|}\sum_{(i,j)\in\mathcal{R}^{b i
n(x),\{1\}}}{\mathcal{E}}[i,j],\] 其中,\({\mathcal{R}}\)是\({\mathcal{E}}\)的整数坐标集合,\({\mathcal{X}}\)是X的下采样预测图,以匹配与\({\mathcal{R}}\)相同的分辨率。这里,\(\mathcal{R}^{b i
n(x),\{1\}}\)表示由预测X分割区域在嵌入空间中的坐标集合。对于所有i,其代表性特征可以表示为\({\mathcal{G}}_{i}=g(X_{i})\)。
随后,我们对代表性特征进行聚类。聚类基于这样的假设:SAFIRE模型能够准确提取特征,从而将来自同一源区域的特征聚集在一起。我们将{G1,···,GN
}聚类为M个簇C1,···,CM。可以应用任何聚类算法,M可以预先固定或由算法回归确定。对于一般的源区域划分,我们可以允许算法确定合适的M。在已知源数量的情况下,可以使用具有固定簇数的算法。
之后,从每个聚类中选择置信度最高的掩模。每个聚类代表输入图像的一个源区域,而置信度最高的掩模对应于该区域的最佳预测。我们收集每个聚类的最大置信度分数的索引:
\[j^{*}=\arg\operatorname*{max}_{\mathcal{G}_{i}\in
C_{j}}s_{i}.\]
最后,将这些掩码组合起来以获得最终预测。最简单的方法是采用softmax:
\[X^{*}=\operatorname{sofmax}\{X_{1^{*}},\cdot\cdot\cdot,X_{M^{*}}\}.\]
对于M =
2的特殊情况,为了获得二进制预测图,两个预测值的简单平均产生一个有效输出:
\[X^{*}=\frac{1}{2}\{\sigma(X_{1^{*}})+(1-\sigma(X_{2^{*}}))\}.\]
4. 二元IFL实验
我们首先从传统的图像中定位伪造区域的任务开始。请注意,SAFIRE可以进行二进制预测和多源预测。
4.1 实验设置
实施细节。
我们的模型先进行预训练,再进行训练。等式(1)中的区域到区域对比学习温度τ设置为0.1。等式(4)中AASS损失的权重上限CAASS设置为10,而等式(6)中的λconf设置为0.1。在推理阶段,M固定为2以获得二进制形式的预测。我们使用16×16个点提示和k均值聚类。
数据集。
我们使用一个常见的设置(Guillaro等人,2023)来训练网络,该设置包含了四个数据集(Kniaz,
Knyaz, and Remondino 2019; Novozamsky, Mahdian, and Saic 2020; Dong,
Wang, and Tan 2013; Kwon et
al.2022),其由真实和虚假图像组成,也被称为CAT-Net(Kwon等人,2022)设置。我们使用五个与训练数据集没有重叠的公开数据集来测试性能:
Columbia (Ng, Chang, and Sun 2004),
COVERAGE (Wen et al. 2016),
CocoGlide (Guillaro et al.2023),
RealisticTampering
(Korus and Huang 2016),
NC16 (Guan et al. 2019)。
这些数据集包含多种伪造类型,包括拼接、复制移动、移除和使用生成模型添加对象。在测试过程中,图像以原始形式输入,但NC16数据集除外,由于某些比较方法的内存限制,图像被缩小了。
比较方法。
根据(Guillaro等,2023)的协议,我们通过选择具有公开可访问代码和预训练模型的最新技术来确保公平比较,这些模型是在测试集的不同数据集上训练的。具体包括
ManTra-Net (Wu,AbdAlmageed, and Natarajan 2019),
SPAN (Hu et
al.2020),
AdaCFA (Bammey, Gioi, and Morel 2020),
CATNet
v2 (Kwon et al. 2022), IF-OSN (Wu et al. 2022),
MVSS-Net (Dong et
al. 2022), PSCC-Net (Liu et al. 2022),
TruFor (Guillaro et al.
2023),
NCL (Zhou et al.
2023a)。
此外,我们还使用了在同一数据集上训练的纯SAM(Kirillov等,2023)模型。
度量。
我们以与TruFor(Guillaro等人,2023)论文相同的方式评估定位性能。具体而言,性能报告采用置换F1分数(Huh等人,2018;Kwon等人,2022),使用固定0.5阈值(F1
fixed)和每张图像的最佳阈值(F1 best)。
4.2 评价结果
表1展示了二进制IFL性能的比较分析。
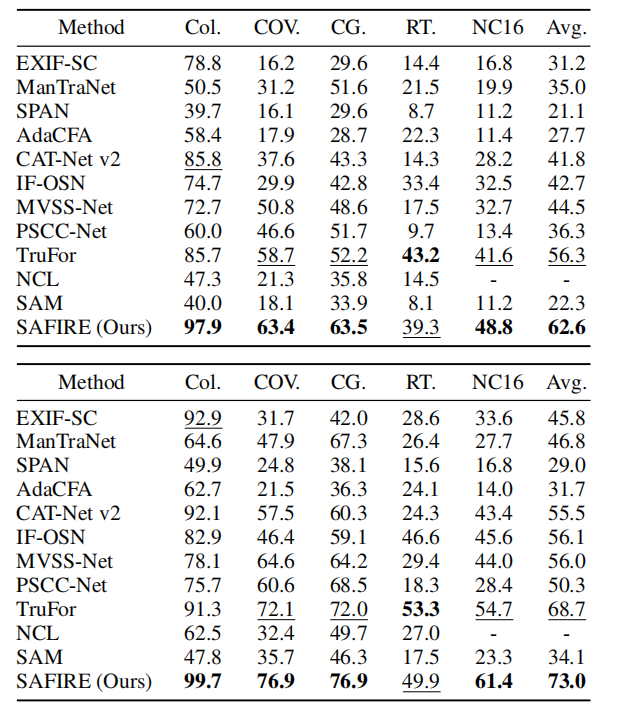
连字符(‘-’)表示该数据集用于训练,因此被排除在外。值得注意的是,SAFIRE在F1固定和F1最佳两个指标上均表现出色,在五个数据集中有四个获得了第一名。此外,所有数据集的平均得分再次证实了SAFIRE的优越性,使其在整体性能上稳居首位。另外,在附录中可以看到,我们的方法在各种全局后处理条件下也优于其他技术,证明了其稳健性。
图6显示了每个模型产生的IFL的定性结果。
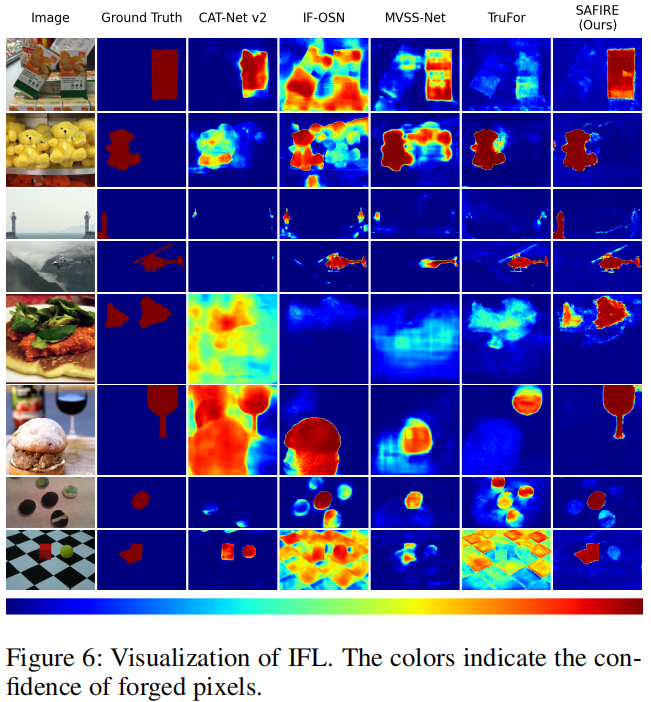
SAFIRE成功识别了其他技术未能检测到的复杂且具有挑战性的操作,并且假阳性检测较少。特别是,与其它技术相比,SAFIRE在复杂的人工智能生成的部分操作中实现了显著更准确的预测。
4.3 消融研究
为了保证我们研究的完整性,我们对框架的关键组件进行了消融研究:区域到区域对比损失、区域自适应源分割损失中的区域自适应特征、点提示和置信度损失(表2)。
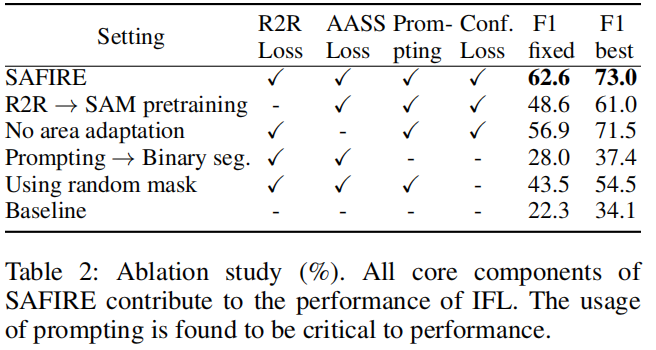
我们用常规的对应物来代替每一个进行比较。
结果表明,在没有任何一个组件的情况下,性能会比完整的SAFIRE框架差,后者集成了所有四个组件。此外,排除所有四个关键特征的基线模型表现出显著较差的结果,这突显了这四个组件在SAFIRE中不可或缺的作用。
特别是,我们观察到基于提示的源区域划分优于二值分割。具有相同结构和预训练的模型在使用二值分割时,仅能达到28.0%的固定F1分数。然而,当采用提示进行源区域划分时,模型性能显著提升,达到62.6%。这证明了SAFIRE的提示方法在使网络理解同一源区域特征方面的有效性,从而实现稳定学习和卓越表现。
5. 多源分区实验
6.结论
SAFIRE通过将图像划分为多个原始区域,解决了通过二进制分割查看IFL任务的传统方法的问题。通过区域间的对比预训练,我们引导编码器有效地嵌入源分区所需的微妙信号。我们利用基于点提示的分割来训练SAFIRE模型,使其能够准确预测每个点所在的源区域。在推理过程中,我们以网格格式提供点提示,并汇总输出以获得最终预测结果。经过全面评估,SAFIRE成功解决了IFL中的标签无关性问题,并超越了其他最先进方法。它还为图像分区中使用点提示开辟了可能性,并提出了将图像划分为多个源区域的新挑战。这有助于理解伪造图像的结构,促进进一步分析。我们希望我们的研究能为解决AI时代日益复杂的图像伪造问题做出贡献。