SAM
Segment Anything

论文(arxiv)
摘要
我们介绍了分段任意事物(SA, Segment Anything)项目:一个新的图像分割任务、模型和数据集。在数据收集循环中使用我们的高效模型,我们建立了迄今为止(迄今为止)最大的分割数据集,在11M许可和尊重隐私的图像上有超过10亿个面具。该模型的设计和训练是及时的,因此它可以转移零镜头到新的图像分布和任务。我们评估了它在许多任务上的能力,发现它的零样本性能令人印象深刻——通常与之前的完全监督结果竞争,甚至更好。
Segment Anything Model
接下来,我们将描述用于快速分割的分段任何东西模型(SAM, Segment Anything Model)。
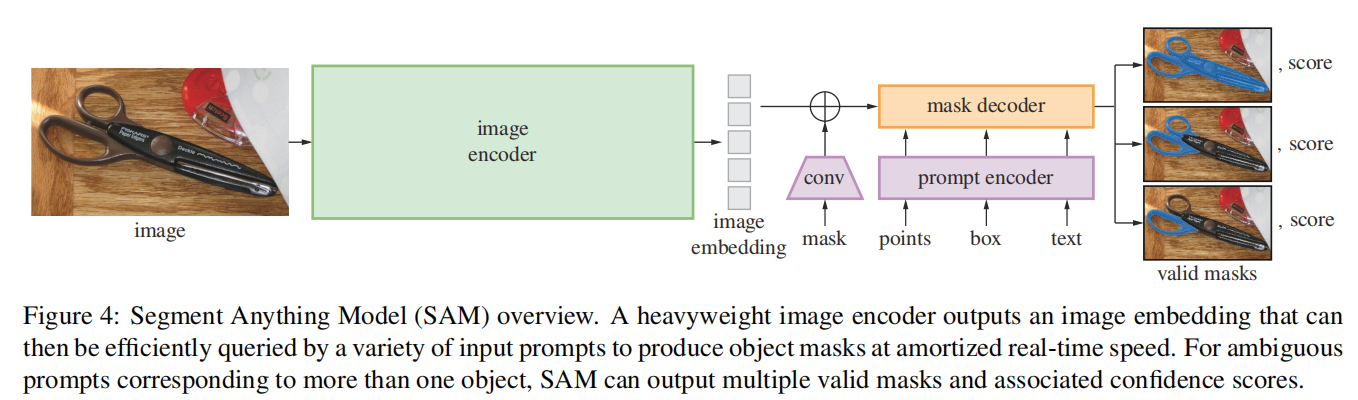 图4:分段任何东西模型(SAM)概述。重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询,以平摊的实时速度产生对象掩模。对于对应于多个对象的模糊提示,SAM可以输出多个有效的掩码和相关的置信度分数。
图4:分段任何东西模型(SAM)概述。重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询,以平摊的实时速度产生对象掩模。对于对应于多个对象的模糊提示,SAM可以输出多个有效的掩码和相关的置信度分数。
SAM有三个组件,如图4所示:图像编码器、灵活的提示编码器和快速掩码解码器。我们建立在转换视觉模型[14,33,20,62]上,对(摊销)实时性能进行特定的权衡。我们在这里高级描述这些组件,在a中详细说明。
图像编码器
一般来说,图像编码器可以是任何输出C×H×W图像嵌入的网络。基于可伸缩性和强大的预训练,我们使用MAE [47]预训练视觉transformer(ViT)[33],具有最小的适应来处理高分辨率输入,特别是ViT-H/16,有14×14窗口注意和4个等间隔的[62]块。图像编码器的输出是输入图像的16×缩小嵌入。由于我们的运行时目标是实时处理每个提示,因此我们可以提供大量的图像编码器片段,因为它们每幅图像只计算一次,而不是每个提示计算一次。根据标准的实践(例如,[40]),我们使用了1024×1024的输入分辨率,这是通过重新缩放图像和填充较短的边而获得的。因此,图像嵌入值为64×64。为了减少信道维度,在[62]之后,我们使用1×1卷积得到256个通道,然后使用3×3卷积得到256个通道。每个卷积之后都是一个层的归一化[4]。
提示编码器
稀疏提示被映射到256维的向量嵌入如下。
一个点被表示为该点的位置的位置编码[95]和两个学习嵌入之一的总和,这表明该点是在前景中还是在背景中。
盒子由嵌入对表示: (1)其左上角的位置编码与表示“左上角”的学习嵌入求和,(2)相同的结构,但使用学习嵌入表示“右下角”。最后,为了表示自由形式的文本,我们使用CLIP [82]的文本编码器(任何文本编码器都是可能的)。我们将在本部分的其余部分中关注几何提示,并在D.5中深入讨论文本提示。
密集的提示(即掩码)与图像具有空间对应关系。我们以比输入图像低4×的分辨率输入掩模,然后使用两个2×2,步幅-2卷积分别与输出通道4和16缩小额外的4×。最后的1×1卷积将通道维度映射到256。每一层通过GELU激活[50]和层归一化分开。然后,将按元素的方式添加图像嵌入和掩码。如果没有掩码提示,则在每个图像嵌入位置添加一个表示“无掩码”的学习嵌入。
轻量级掩码器
该模块有效地将图像嵌入和一组提示嵌入映射到一个输出掩码。为了结合这些输入,我们从transformer分割模型[14,20]中获得灵感,并修改了一个标准的transformer解码器[103]。在应用我们的解码器之前,我们首先在提示嵌入集中嵌入一个学习到的输出tokens嵌入,该嵌入将用于解码器的输出,类似于[33]中的[类]tokens。为简单起见,我们将这些嵌入(不包括图像嵌入)统称为“标记”。
我们的解码器设计如图14所示。
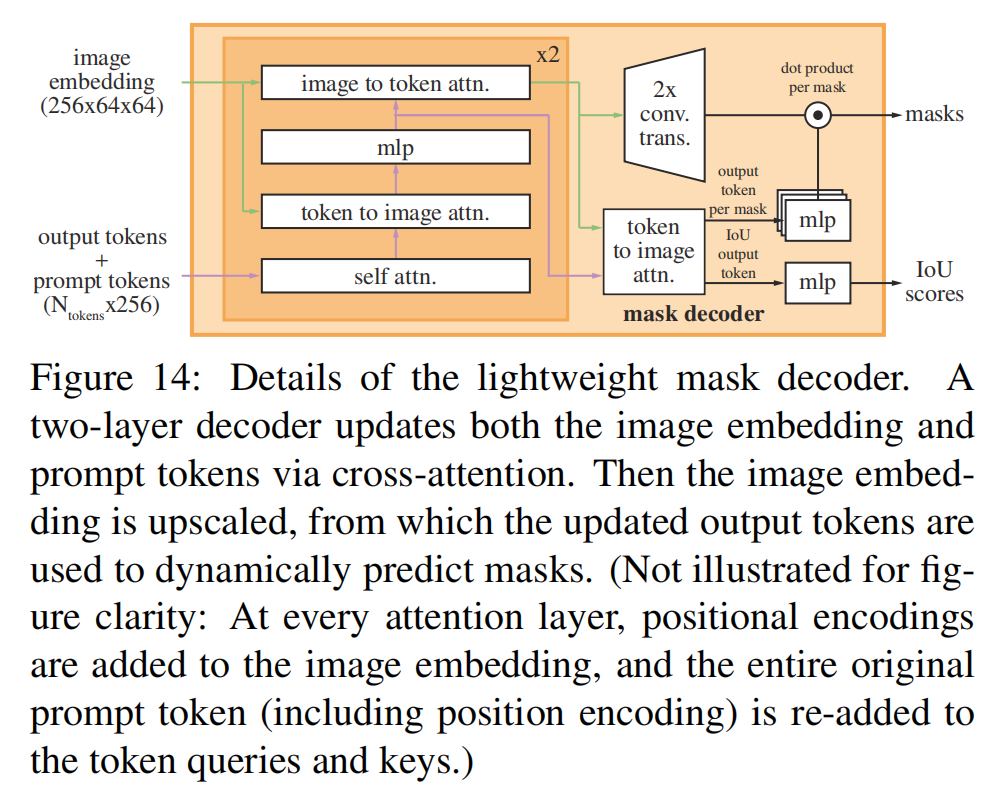
图14:轻量级掩码解码器的细节。一个两层解码器通过交叉注意来更新图像嵌入和提示标记。然后对图像嵌入进行升级,利用更新后的输出标记来动态预测掩模。(为了图形清晰度,没有说明:在每个注意层,位置编码被添加到图像嵌入中,整个原始提示tokens(包括位置编码)被重新添加到tokens查询和键中。)
每个解码器层执行4个步骤:(1)对标记的自我注意,(2)从标记(作为查询)交叉注意到图像嵌入,(3)点级MLP更新每个标记,以及(4)从图像嵌入(作为查询)交叉注意到标记。这最后一步将使用提示信息更新图像嵌入。在交叉注意过程中,将图像嵌入视为一组64225个6维向量。每个自我/交叉注意和MLP都有一个残差连接[49]、层归一化和退出[93]为0.1。下一个解码器层从上一层中获取更新的tokens和更新的图像嵌入。我们使用了一个两层解码器。
为了确保解码器能够访问关键的几何信息,当位置编码参与注意层时,它们将被添加到图像嵌入中。此外,整个原始提示标记(包括它们的位置编码)都会被重新添加到更新后的标记中。这允许强烈地依赖于提示tokens的几何位置和类型。
在运行解码器后,我们用两个转置卷积对更新后的图像嵌入上采样,即4×(现在它相对于输入图像缩小了4×)。然后,tokens再次关注图像嵌入,我们将更新后的输出tokens嵌入传递给一个小的3层MLP,该MLP输出一个与升级图像嵌入的通道维数相匹配的向量。最后,我们预测了一个在升级的图像嵌入和MLP的输出之间具有空间点级乘积的掩模。
该transformer使用的嵌入尺寸为256。Transformer MLP块有一个很大的内部尺寸为2048,但MLP只应用于有相对较少(很少大于20)的提示tokens。在交叉注意层中,我们有一个64×64的图像嵌入,为了提高计算效率,我们将查询、键和值的通道维数降低两倍到128。所有的注意力层都使用8个头。用于升级输出图像嵌入的转置卷积为2×2,步幅为2,输出通道尺寸分别为64和32,并具有GELU激活。它们被层归一化分开。
SAM-Adapter
《SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in
Underperformed Scenes: Camouflage, Shadow, Medical Image
Segmentation,and More》
![]()

该文指出号称可以“分割一切”的SAM模型虽然在自然图像的通用分割任务中取得了优异的效果,但在许多特殊图像的特定分割任务上表现差强人意,如水下目标分割、阴影分割、伪装对象分割等。作者认为这是由于SAM主要在常见的自然图像中进行训练,其特征提取器不能很好的适应特殊图像。因此作者提出一种轻量化的适配器模块(Adaptor),对SAM的编码器得到的特征图进行适应性调整。编码器的输入为特定任务信息,该文采用了图块嵌入特征和高频成分特征,将两种特征相加后经过两个MLP层得到适配器模块的输出,并将该输出与对应SAM编码器的Transformer层输出相加,并传递至下一层。训练过程中SAM编码器的参数保持不变,解码器部分使用SAM的参数进行初始化,然后利用特定数据集进行微调。
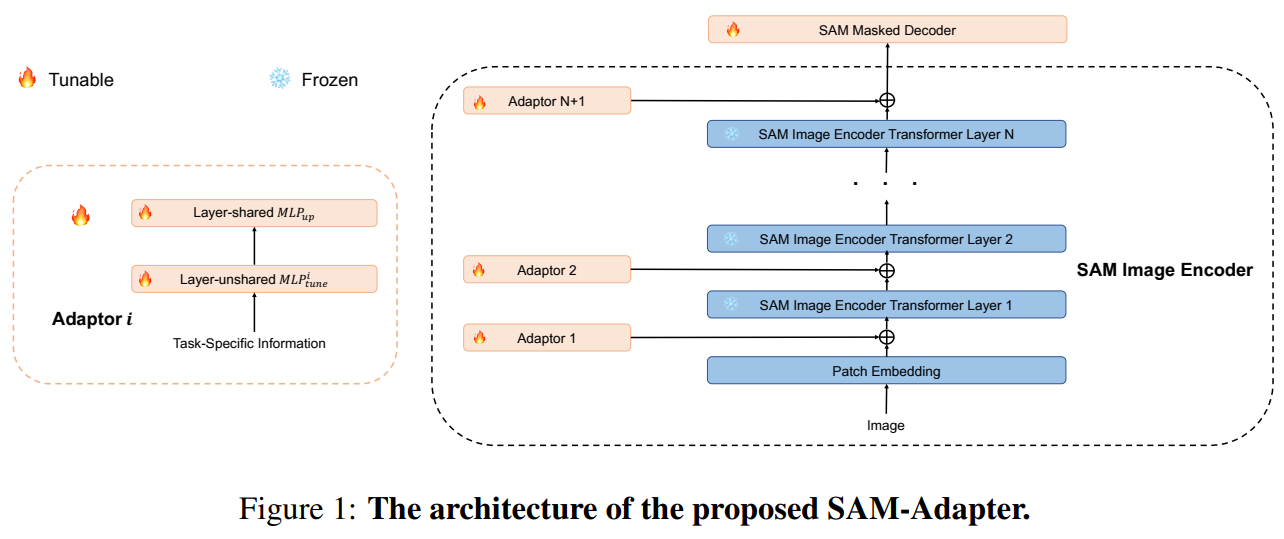
如上图所示,该模型使用了SAM的图像编码器和掩模解码器,其中图像编码器冻结了参数,解码器是参与梯度回传的。这样可以有效利用SAM已经预训练好的分割能力,同时解码器更新参数以改装下游任务。另外引入了Adaptor模块,用于引入特殊任务的知识,辅助适配器模型。Adaptor的网络结构由两层MLP层构成,其输入的知识可以是微处理器的,对于文中的任务,其输入可以是纹理信息或者是频率信息等。各种信息用下面的权重来均衡。
该文提出的Adaptor模块包括所使用的两个特定任务信息——图块嵌入特征和高频成分特征,都是来源于另一篇论文《Explicit Visual Prompting for Low-Level Structure Segmentations》(EVP)。图块嵌入特征就是将图片划分成若干个图块,利用ViT将其映射为一个 $ C_{seg} $ 维的特征;高频成分特征,则是将图片进行快速傅里叶变换,并保留其中的高频成分,再进行反变换得到高频成分对应的时域图,最后经过一个线性映射层得到一个特征向量。
实验表明,在多个任务中SAM-Adapter均取得了远超SAM的表现,甚至由于各自领域的其他优秀算法,作为SAM的一种改进思路还是有值得借鉴和学习的地方。然而,整篇论文的思路几乎完全照搬了EVP,只是将模型从SegFormer换成了SAM,其他并没有明显改变。但在实验章节的算法效果对比中却回避了EVP,尤其是有些结果还不如EVP,这就很让人质疑其原创性和先进性。