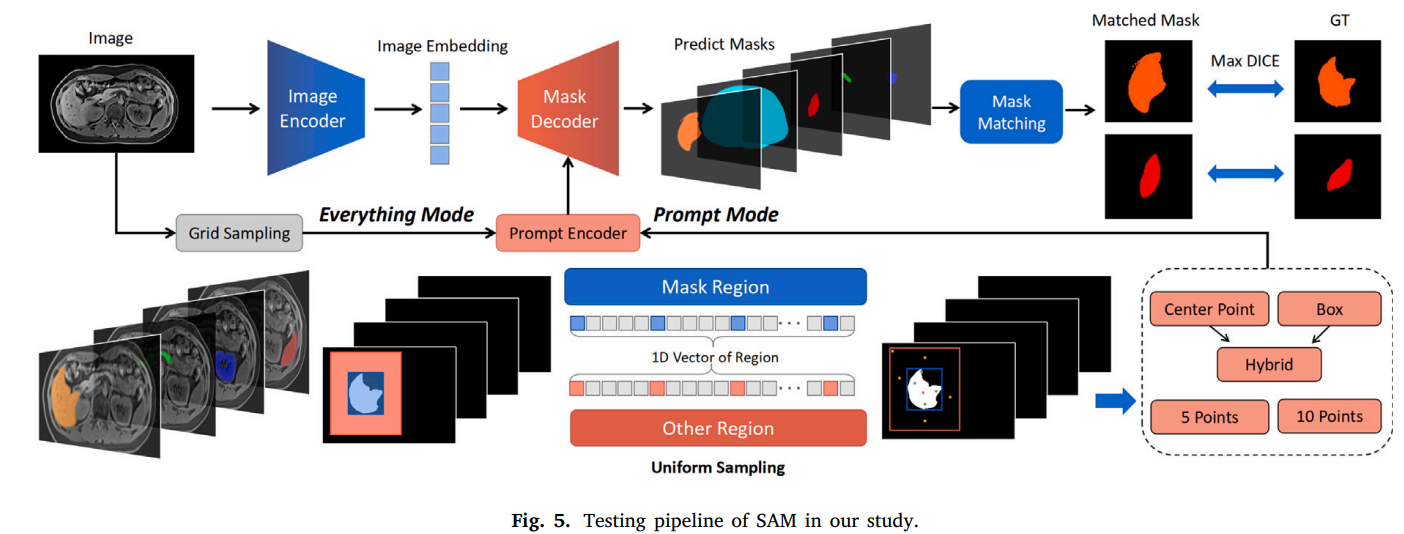
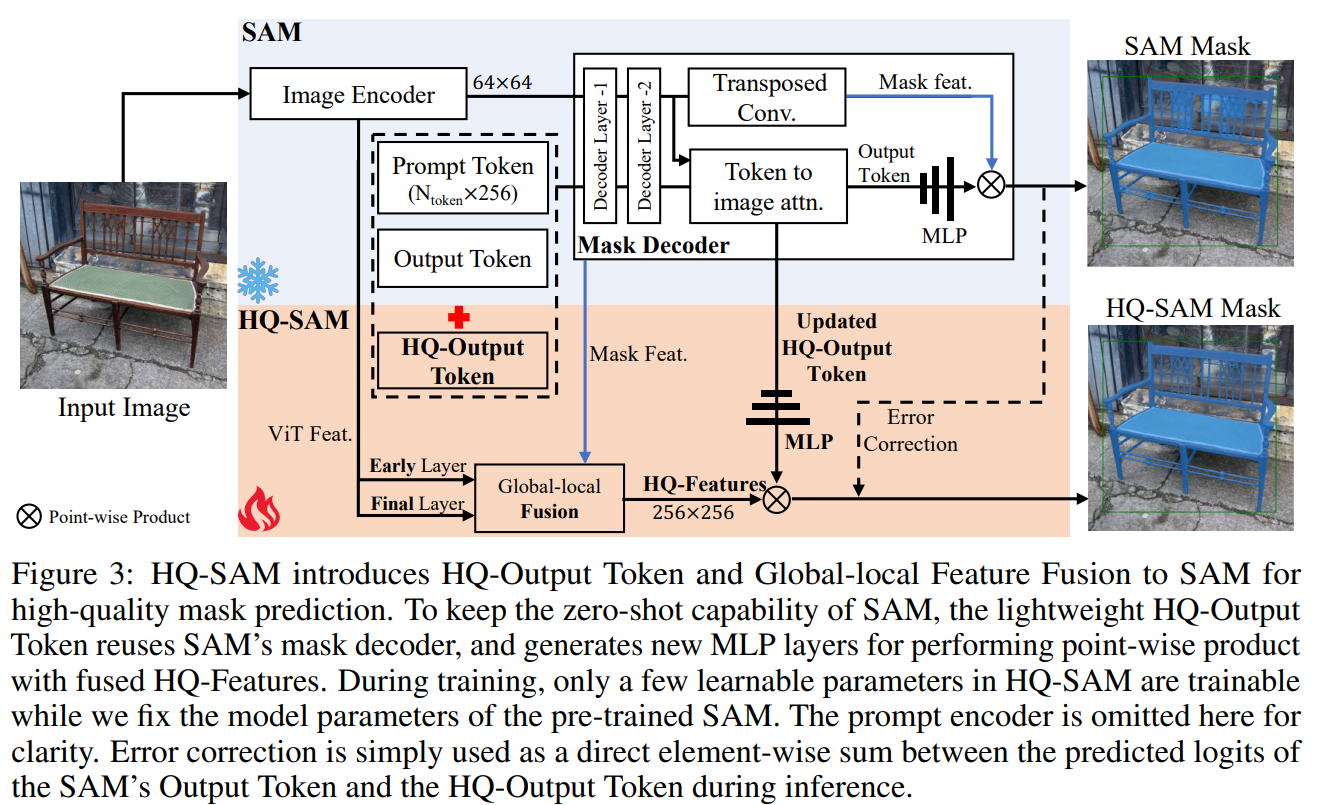
train with box、point、noise_mask
接下来是的代码来自
https://github.com/SysCV/SAM-HQ
任务是SAM的高质量掩模预测问题
------------------------------------------------------------------------------------------------------------
from utils.loss_mask import loss_masks
net = MaskDecoderHQ(args.model_type)
------------------------------------------------------------------------------------------------------------
if input_type == 'box':
dict_input['boxes'] = labels_box[b_i:b_i+1]
elif input_type == 'point':
point_coords = labels_points[b_i:b_i+1]
dict_input['point_coords'] = point_coords
dict_input['point_labels'] = torch.ones(point_coords.shape[1], device=point_coords.device)[None,:]
elif input_type == 'noise_mask':
dict_input['mask_inputs'] = labels_noisemask[b_i:b_i+1]
else:
raise NotImplementedError
dict_input['original_size'] = imgs[b_i].shape[:2]
batched_input.append(dict_input)
with torch.no_grad():
batched_output, interm_embeddings = sam(batched_input, multimask_output=False)
batch_len = len(batched_output)
encoder_embedding = torch.cat([batched_output[i_l]['encoder_embedding'] for i_l in range(batch_len)], dim=0)
image_pe = [batched_output[i_l]['image_pe'] for i_l in range(batch_len)]
sparse_embeddings = [batched_output[i_l]['sparse_embeddings'] for i_l in range(batch_len)]
dense_embeddings = [batched_output[i_l]['dense_embeddings'] for i_l in range(batch_len)]
masks_hq = net(
image_embeddings=encoder_embedding,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=False,
hq_token_only=True,
interm_embeddings=interm_embeddings,
)
loss_mask, loss_dice = loss_masks(masks_hq, labels/255.0, len(masks_hq))
loss = loss_mask + loss_dice
loss_dict = {"loss_mask": loss_mask, "loss_dice":loss_dice}
# reduce losses over all GPUs for logging purposes
loss_dict_reduced = misc.reduce_dict(loss_dict)
losses_reduced_scaled = sum(loss_dict_reduced.values())
loss_value = losses_reduced_scaled.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
metric_logger.update(training_loss=loss_value, **loss_dict_reduced)
------------------------------------------------------------------------------------------------------------
loss_masks:
------------------------------------------------------------------------------------------------------------
def loss_masks(src_masks, target_masks, num_masks, oversample_ratio=3.0):
"""Compute the losses related to the masks: the focal loss and the dice loss.
targets dicts must contain the key "masks" containing a tensor of dim [nb_target_boxes, h, w]
"""
# No need to upsample predictions as we are using normalized coordinates :)
with torch.no_grad():
# sample point_coords
point_coords = get_uncertain_point_coords_with_randomness(
src_masks,
lambda logits: calculate_uncertainty(logits),
112 * 112,
oversample_ratio,
0.75,
)
# get gt labels
point_labels = point_sample(
target_masks,
point_coords,
align_corners=False,
).squeeze(1)
point_logits = point_sample(
src_masks,
point_coords,
align_corners=False,
).squeeze(1)
loss_mask = sigmoid_ce_loss_jit(point_logits, point_labels, num_masks)
loss_dice = dice_loss_jit(point_logits, point_labels, num_masks)
del src_masks
del target_masks
return loss_mask, loss_dice
------------------------------------------------------------------------------------------------------------
get_uncertain_point_coords_with_randomness:
"""
Sample points in [0, 1] x [0, 1] coordinate space based on their uncertainty. The unceratinties
are calculated for each point using 'uncertainty_func' function that takes point's logit
prediction as input.
See PointRend paper for details.
Args:
coarse_logits (Tensor): A tensor of shape (N, C, Hmask, Wmask) or (N, 1, Hmask, Wmask) for
class-specific or class-agnostic prediction.
uncertainty_func: A function that takes a Tensor of shape (N, C, P) or (N, 1, P) that
contains logit predictions for P points and returns their uncertainties as a Tensor of
shape (N, 1, P).
num_points (int): The number of points P to sample.
oversample_ratio (int): Oversampling parameter.
importance_sample_ratio (float): Ratio of points that are sampled via importnace sampling.
Returns:
point_coords (Tensor): A tensor of shape (N, P, 2) that contains the coordinates of P
sampled points.
"""
point_sample:
"""
A wrapper around :function:`torch.nn.functional.grid_sample` to support 3D point_coords tensors.
Unlike :function:`torch.nn.functional.grid_sample` it assumes `point_coords` to lie inside
[0, 1] x [0, 1] square.
Args:
input (Tensor): A tensor of shape (N, C, H, W) that contains features map on a H x W grid.
point_coords (Tensor): A tensor of shape (N, P, 2) or (N, Hgrid, Wgrid, 2) that contains
[0, 1] x [0, 1] normalized point coordinates.
Returns:
output (Tensor): A tensor of shape (N, C, P) or (N, C, Hgrid, Wgrid) that contains
features for points in `point_coords`. The features are obtained via bilinear
interplation from `input` the same way as :function:`torch.nn.functional.grid_sample`.
"""
sigmoid_ce_loss_jit = torch.jit.script(
sigmoid_ce_loss
) # type: torch.jit.ScriptModule
def sigmoid_ce_loss(
inputs: torch.Tensor,
targets: torch.Tensor,
num_masks: float,
):
"""
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary
classification label for each element in inputs
(0 for the negative class and 1 for the positive class).
Returns:
Loss tensor
"""
loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
return loss.mean(1).sum() / num_masks
dice_loss_jit = torch.jit.script(
dice_loss
) # type: torch.jit.ScriptModule
def dice_loss(
inputs: torch.Tensor,
targets: torch.Tensor,
num_masks: float,
):
"""
Compute the DICE loss, similar to generalized IOU for masks
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary
classification label for each element in inputs
(0 for the negative class and 1 for the positive class).
"""
inputs = inputs.sigmoid()
inputs = inputs.flatten(1)
numerator = 2 * (inputs * targets).sum(-1)
denominator = inputs.sum(-1) + targets.sum(-1)
loss = 1 - (numerator + 1) / (denominator + 1)
return loss.sum() / num_masks
------------------------------------------------------------------------------------------------------------
|