SIDA:Social Media Image Deepfake Detection, Localization and Explanation with Large Multimodal Model

SIDA: Social Media Image Deepfake Detection, Localization and Explanation with Large Multimodal Model
Zhenglin Huang1 Jinwei Hu1 Xiangtai Li 2 † Yiwei He1 Xingyu Zhao3 Bei
Peng1 Baoyuan Wu4 Xiaowei Huang1 Guangliang Cheng1 †
1英国University
of Liverpool
2新加坡南洋理工大学
3WMG, University of Warwick
4中国香港中文大学(深圳校区,广东省)
项目页:https://hzlsaber.github.io/projects/SIDA/
†
通讯作者。电子邮箱: guangliang.cheng@liverpool.ac.uk
xiangtai94@gmail.com
摘要
生成式模型在创建高度逼真图像方面的快速发展,为虚假信息传播带来了重大风险。例如,合成图像一旦在社交媒体上被分享,就可能误导大量受众,削弱数字内容的信任度,导致严重后果。尽管取得了一定进展,学术界仍未为社交媒体创建大规模、多样化的深度伪造检测数据集,也未提出有效解决方案。
本文提出社交媒体图像检测数据集(SID-Set),该数据集具有三大优势:
(1)海量数据,包含30万张AI生成/篡改及真实图像,并附有全面标注;
(2)多样性广,涵盖各类完全合成与篡改图像;
(3)逼真度高,图像经视觉检查几乎无法与真实图像区分。
此外,我们利用大型多模态模型的卓越能力,提出名为SIDA(社交媒体图像检测、定位与解释助手)的新型图像深度伪造检测、定位及解释框架。SIDA不仅能识别图像真实性,还能通过掩码预测标注篡改区域,并提供模型判断标准的文本解释。与SID-Set及其他基准测试中的最先进深度伪造检测模型相比,大量实验表明SIDA在多样化场景中表现出更优的性能。相关代码、模型及数据集将予以公开发布。
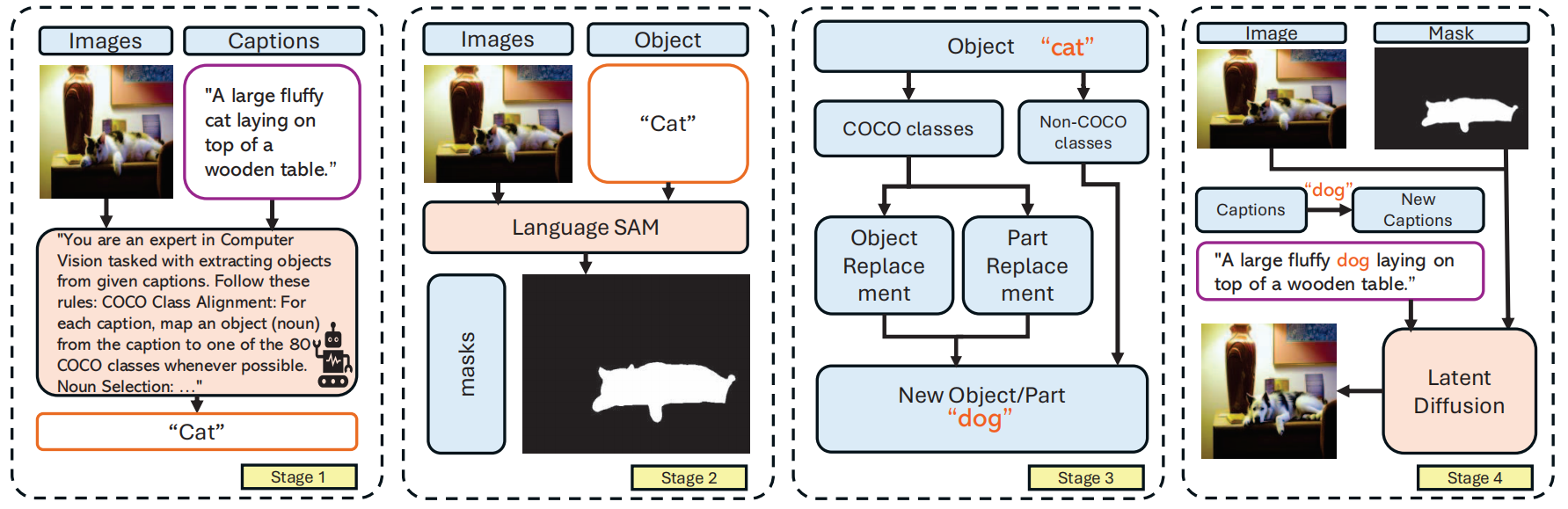
图3. 伪造图像生成流程:该流程包含四个阶段——首先使用GPT-4o从标题中提取对象,接着通过Language-SAM获取对象掩码,随后建立替换词典以生成伪造图像,最后采用Latent Diffusion生成新图像。图中展示了对象替换(如将“猫”替换为“狗”)和属性修改的示例。
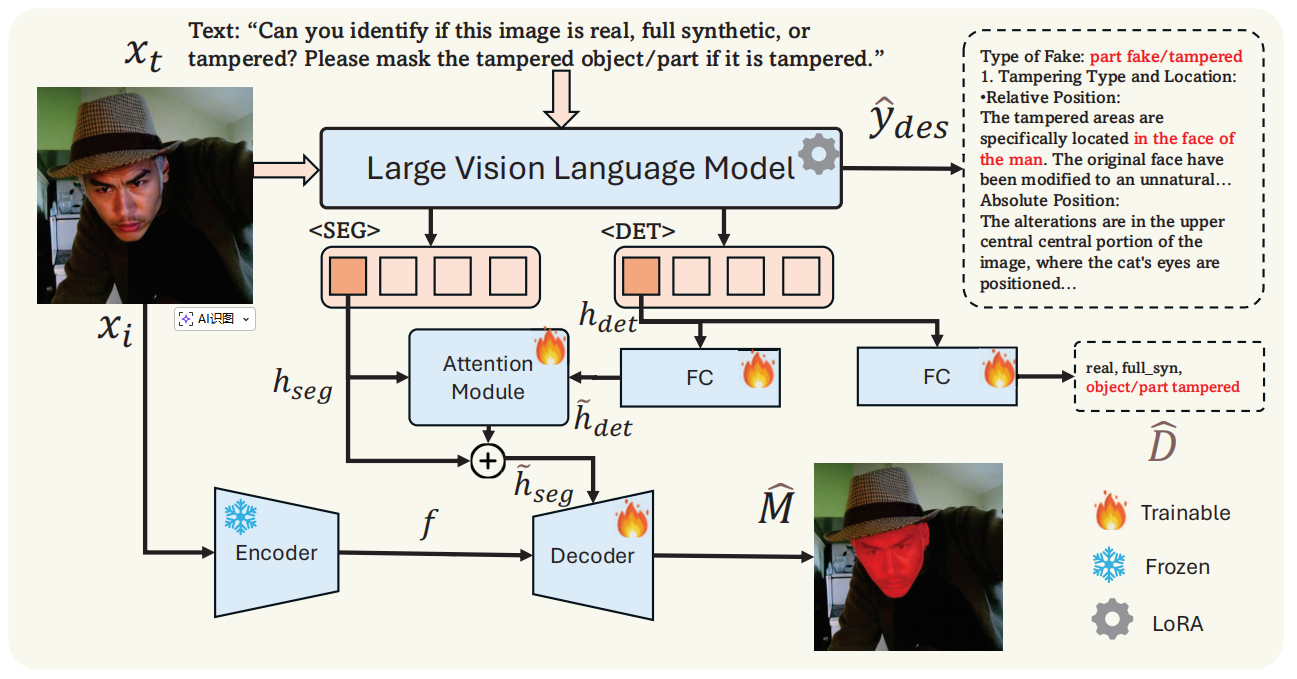
图5. SIDA的处理流程:当输入图像xi和对应文本xt时,
标记的最后一个隐藏层会生成检测结果。若检测结果提示图像存在篡改,SIDA将提取 标记以生成篡改区域的掩码。图中展示了一个男性面部被篡改的示例。