SegFormer
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Enze Xie1, Wenhai Wang2, Zhiding Yu3, Anima Anandkumar3,4, Jose M. Alvarez3, Ping Luo1
摘要
我们提出SegFormer,这是一个简单、高效且强大的语义分割框架,它将Transformer与轻量级多层感知机(MLP)解码器统一起来。SegFormer有两个吸引人的特点:1) SegFormer包含一个新型的分层结构化Transformer编码器,可输出多尺度特征。该编码器无需位置编码,从而避免了位置编码的插值操作——当测试分辨率与训练分辨率不同时,这种插值操作会导致性能下降。2) SegFormer摒弃了复杂的解码器设计。我们提出的多层感知机(MLP)解码器通过整合不同层级的信息,将局部注意力与全局注意力相结合,从而生成强大的表征特征。实验证明,这种简洁轻量的设计正是实现Transformer模型高效分割的关键所在。我们通过扩展SegFormer-B0到SegFormer-B5系列模型,取得了显著优于前代方法的性能和效率。例如,SegFormer-B4在ADE20K数据集上以6400万参数实现了50.3%的平均IoU值,体积缩小5×倍且性能提升2.2%,超越了此前最佳方法。我们的旗舰模型SegFormer-B5在Cityscapes验证集上达到84.0%的平均IoU值,并在Cityscapes-C数据集上展现出出色的零样本鲁棒性。
代码将在以下位置发布:github.com/NVlabs/SegFormer。
1.引言
语义分割是计算机视觉领域的基础性任务,能够支持众多下游应用。由于其输出的是逐像素的类别预测而非全局图像预测,因此与图像分类密切相关。这一关联性在经典研究[1]中得到明确阐述与系统性探讨,该论文采用全卷积网络(FCN)完成语义分割任务。自那时起,全卷积网络不仅启发了大量后续研究,更成为密集预测领域的主流设计方案。由于分类与语义分割存在密切关联,当前众多前沿语义分割框架都是基于ImageNet图像分类主流架构的变体。因此,设计骨干网络架构始终是语义分割领域的研究热点。事实上,从早期使用VGG模型[1,2]的方法,到最新采用深度更强、性能更优骨干网络[3]的技术,骨干网络的演进已显著突破了语义分割的性能极限。除架构设计外,另一研究方向将语义分割视为结构化预测问题,重点设计能有效捕捉上下文信息的模块与运算符。该领域的代表性成果是扩张卷积[4,5]技术,通过在卷积核中添加孔洞来扩大感受野,从而提升网络的感知能力。
随着自然语言处理(NLP)取得重大突破,近期视觉任务领域对Transformer模型的兴趣激增。多索维茨基团队[6]提出视觉Transformer(ViT)用于图像分类,该模型沿用NLP中Transformer的设计思路,将图像分割成多个线性嵌入的区块,并输入带有位置嵌入(PE)的标准Transformer网络,最终在ImageNet数据集上取得了亮眼表现。在语义分割领域,郑等人[7]提出的SETR模型则验证了Transformer在该任务中的应用可行性。
SETR采用ViT作为骨干网络,并通过集成多个CNN解码器来提升特征分辨率。尽管ViT性能优异,但仍存在以下局限:1)输出单一尺度的低分辨率特征而非多尺度特征;2)在处理大尺寸图像时计算成本较高。针对这些问题,王等人[8]提出了金字塔视觉变换器(PVT),这是ViT的自然扩展架构,采用金字塔结构进行密集预测。PVT在目标检测和语义分割任务中相比ResNet架构展现出显著提升。然而,与Swin
Transformer
[9]、Twins[10]等新兴方法类似,这些研究主要聚焦于Transformer编码器的设计优化,而忽视了解码器对性能提升的贡献。
本文提出SegFormer——一种面向语义分割的前沿Transformer框架,该框架在效率、精度和鲁棒性三方面实现协同优化。与现有方法不同,我们对编码器和解码器进行了全新设计。本方案的核心创新点包括:
- 一种新的无位置编码和层次结构的Transformer编码器。
- 一种轻量级的全多层感知器解码器设计,能够在不使用复杂且计算密集型模块的情况下生成强大的表示。
- 如图1所示,SegFormer在三个公开语义分割数据集上,在效率、准确性和鲁棒性方面都达到了新的最高水平。
首先,我们提出的编码器在处理不同分辨率图像进行推理时,避免了对位置编码进行插值操作。因此,该编码器能够轻松适应任意测试分辨率而不影响性能表现。此外,其分层结构使编码器既能生成高分辨率的精细特征,又能生成低分辨率的粗略特征——这与只能生成固定分辨率低分辨率特征图的ViT模型形成鲜明对比。其次,我们提出了一种轻量级多层感知机解码器,其核心思路是利用Transformer生成的特征:低层注意力机制倾向于保持局部性,而高层注意力则具有高度非局部性。通过整合不同层级的信息,多层感知机解码器实现了局部与全局注意力的协同作用。这种设计使我们获得了一个结构简洁、实现高效的解码器,能够生成强大的表征。
我们在三个公开数据集ADE20K、Cityscapes和COCO-Stuff上验证了SegFormer模型在体积、运行时间和精度方面的优势。在Cityscapes数据集上,我们的轻量级模型SegFormer-B0(未采用TensorRT等加速技术)以48帧/秒的运行速度获得71.9%的平均IoU值,相比ICNet
[11]模型分别实现了60%的性能提升和4.2%的延迟优化。最大规模的SegFormer-B5模型不仅达到84.0%的IoU值,其运行速度比SETR
[7]快5×倍,性能提升达1.8%。在ADE20K数据集上,该模型以51.8%的IoU值刷新了行业纪录,体积却比SETR缩小4×倍。此外,我们的方法对常见图像篡改和扰动具有更强的鲁棒性,特别适合安全关键型应用场景。相关代码将对外公开。
3.方法
本节将介绍SegFormer——一个无需人工设计且计算量低的高效、稳健、强大的分割框架。如图2所示,该框架包含两大核心模块:(1)分层Transformer编码器,用于生成高分辨率粗粒度特征和低分辨率细粒度特征;(2)轻量级全多层感知机解码器,通过融合这些多层次特征生成最终的语义分割掩膜。
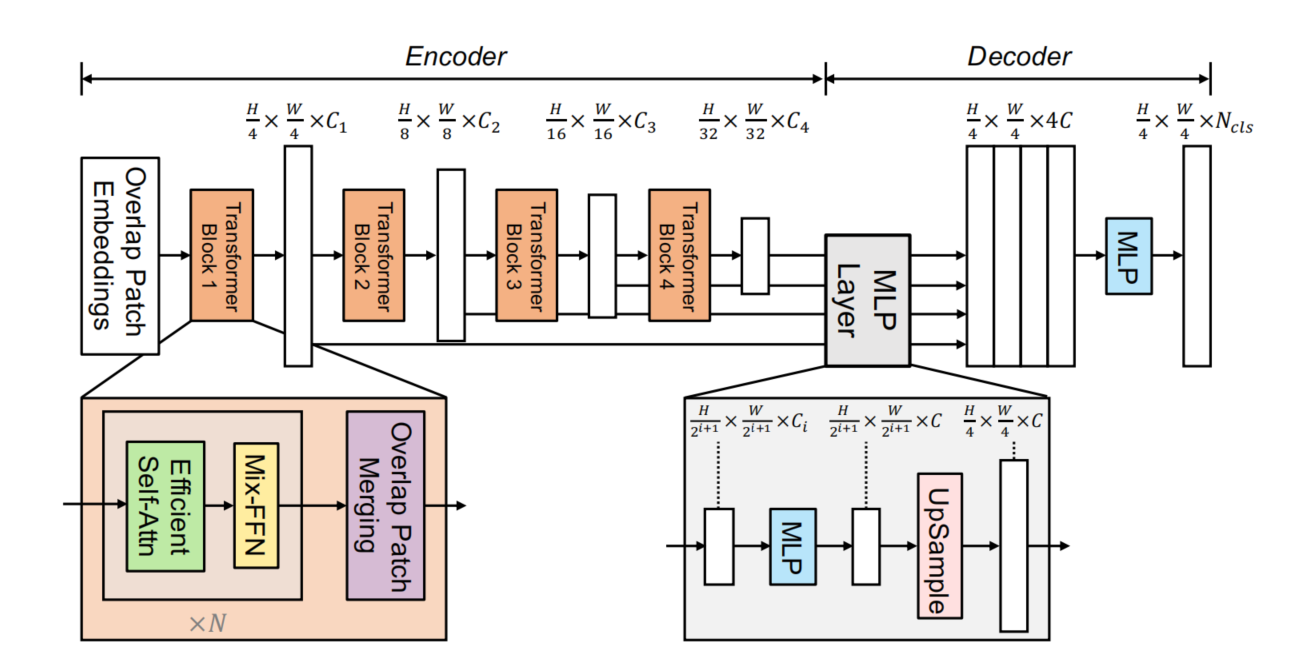
图2:本文提出的SegFormer框架包含两大核心模块——分层Transformer编码器负责提取粗粒度和细粒度特征,轻量级全多层感知机解码器则直接融合这些多层次特征并生成语义分割掩膜。其中“FFN”表示前馈网络。