Segment Every Out-of-Distribution Object

Segment Every Out-of-Distribution Object
Wenjie Zhao1,Jia Li1 ,Xin Dong2 ,Yu Xiang1 ,Yunhui Guo
1
University of Texas at Dallas
2 Harvard University
摘要
语义分割模型虽然在处理同分布类别时效果显著,但在实际应用中却面临挑战——当遇到分布外(OoD)对象时,其性能会明显下降。在安全关键型应用中,检测OoD对象至关重要。现有方法依赖异常分数进行检测,但选择合适的阈值生成掩膜存在困难,容易导致分割碎片化和检测不准确。本文提出了一种名为S2M(异常分数到分割掩膜)的创新方法,为语义分割中的OoD检测提供了一个简单高效的解决方案。与传统像素级异常评分不同,S2M直接对整个异常对象进行分割处理。S2M通过将异常分数转化为可提示分割模型的输入,彻底消除了阈值选择的必要性。大量实验表明,在Fishyscapes、Segment-Me-IfYou-Can和RoadAnomaly等基准数据集上,S2M在交并比(IoU)上平均比现有最佳模型提升约20%,在平均F1分数上提升40%。代码可在 https://github.com/WenjieZhao1/S2M 上获取.
1.引言
语义分割作为计算机视觉领域的关键任务,在自动驾驶、航拍图像分析等众多应用中具有重要价值[18,50]。虽然当前的语义分割模型表现优异,但实际应用中仍面临挑战。主要障碍在于其检测分布外(OoD)对象的能力有限。具体而言,这些模型常将异常数据对象(OoD)中的像素点归入训练时使用的类别,从而导致分割掩膜的准确性不足[26,32,46]。解决语义分割中的异常检测问题至关重要,因为异常检测对象掩模的不准确性可能导致错误结论,最终在自动驾驶等应用中引发安全隐患[3,4,14,38,50]。
现有语义分割中的异常检测方法通过为每个像素分配异常分数来解决这一问题[2,24,32,35,46]。异常分数较高的像素将被视为异常对象的一部分。这些异常分数通常由分割模型对每个像素的概率预测得出[22,25,36]。例如,
PEBAL [46]提出了一种基于像素能量的分割方法来计算异常分数。 RPL
[32]引入了残差模式学习模块,并采用基于能量的方法计算异常分数[46],在不影响数据分布内分割性能的前提下,有效提升了模型对异常像素的敏感度。
虽然基于异常分数的OoD检测方法能精准识别异常像素,但它们缺乏有效分割整个OoD对象的方法。具体而言,要为OoD对象生成掩膜,关键在于使用精心挑选的阈值来区分异常像素与正常像素[9,16,47]。然而在实际应用中,确定最佳阈值可能是个棘手难题。如图2所示,现有OoD检测方法的最佳阈值范围相当狭窄——哪怕阈值稍有偏差(过高或过低),都可能导致分割结果失准。

图2.现有基于异常分数的OoD检测方法(如 RPL [32])对阈值敏感,而S2M无需阈值选择,更具实用性。此外,S2M还能生成更精确的掩码。
选择最佳阈值通常需要专门的验证数据集来微调阈值,但在实际操作中,这类验证数据集往往难以获取。即便采用最优阈值,基于异常分数的OoD检测方法生成的掩膜仍需优化,因为某些像素的异常分数可能存在误差,导致生成的掩膜出现碎片化或不连续现象。

图1. 与当前最先进的语义分割异常检测方法相比,我们的方法在生成高质量异常检测对象掩膜方面表现突出。顶部行展示了多张真实场景图像,蓝色边框框选出了异常对象。后续行展示了不同方法生成的异常检测对象掩膜,包括 PEBAL [46]、 RPL [32]和我们的S2M方法。对于 PEBAL 和 RPL ,掩膜是通过使用各数据集专属的最优阈值从异常分数中生成的。与其他方法常在异常对象外产生噪声并呈现碎片化掩膜不同,S2M能为异常检测对象生成精准的掩膜。
图1展示了 PEBAL [46]和 RPL
[32]两种基于异常分数的最新OoD检测方法生成的各类掩码示例。由于模型用户难以准确定位OoD对象,这些碎片化掩码几乎无法发挥作用。
本文提出了一种名为S2M(Score-to-Mask)的创新方法,该方法通过将异常分数直接转换为分割掩膜,为语义分割领域构建了一个简单通用的分布外(OoD)检测框架。与传统基于阈值处理异常分数生成掩膜的方法不同,S2M专注于对整个分布外对象进行完整分割。这种创新设计有效缓解了传统阈值方法导致的分割碎片化问题。具体来说,S2M系统会利用现有的异常检测方法生成的异常分数,通过提示生成器从中提取出对应的框提示。生成的框选提示将大致定位异常数据对象。随后,这些框选提示被输入到可提示分割模型中,用于生成异常检测对象的掩码。图1展示了S2M生成的多个异常检测对象掩码示例。与传统阈值分割方法不同,S2M生成的掩码能精准分割整个异常检测对象,同时避免正常像素被误判。相较于现有异常检测方法,S2M具有三大优势:1)简洁性:S2M采用简单流程设计,无需超参数调优,训练部署便捷;2)通用性:可与各类基于异常分数的检测方法无缝集成,生成高质量异常检测掩码;3)高效性:能精准分割异常检测对象,避免生成碎片化或失真掩码。
本文的贡献如下:
- 我们提出了S2M,这是一种简单通用的流程,用于生成离散对象的精确掩码。
- 我们省去了手动选择生成分割掩膜的最佳阈值的步骤,这一步骤通常会增加部署的复杂性。此外,我们的方法具有通用性,不依赖于特定的异常分数、提示生成器或可提示分割模型。
- 我们对S2M在Fishyscapes、Segment-Me-If-You-Can和RoadAnomaly等常用OoD分割基准数据集上进行了全面评估,结果显示:在所有基准测试中,S2M平均将交并比(IoU)提升约20%,平均F1分数提升40%,显著超越现有最优方案。
2.相关工作
语义分割
语义分割作为计算机视觉领域的关键任务,近年来取得了显著进展[13,19,21,26,43]。传统上,该领域主要依赖像素级分类方法,尤其是受全卷积网络(FCN)[33]的推动。这些方法通过保留图像的高层次特征并整合多尺度上下文信息,在生成精细分割结果方面表现出色,这一点在各类架构和方法中得到了充分验证。DeepLab系列通过采用扩张卷积来增强感受野,标志着该领域的重要突破。DeepLabv3+
[44]不仅引入了空洞卷积以提升特征提取效果,还配备了解码器模块,能精准优化分割结果,尤其在物体边界处表现突出。
近年来,语义分割领域的发展趋势逐渐转向基于Transformer架构和注意力机制的创新方案,这些技术能更精准地处理图像中的上下文关联[13,45,52]。与传统分割方法不同,基于提示的分割技术开创了独特的范式。其核心优势在于强大的分割能力,能够高效实现图像中物体的精准划分。例如,CLIPSeg[34]开发的系统可基于任意提示(文本或图像)在测试阶段生成图像分割结果,从而为三种不同的分割任务构建统一模型。而Segment
Anything
Model(SAM)[26]则以生成精准物体掩膜的能力著称,在物体分割任务中展现出卓越性能。
像素级OOD检测
像素级OOD检测技术主要基于语义分割模型的输出结果。早期阶段,多数异常检测方法采用数学方法,通过分析分割模型的置信度分布来识别异常像素[27,28,31,49]。例如,基于能量的方法[31]通过在模型中用能量函数替代softmax函数,无需改变模型架构即可获得像素级异常评分,并引入能量正则化项实现模型的精准微调。Synboost[11]通过集成学习权重生成的不确定性图来计算异常评分,既有效提升了异常检测精度,又解决了过度自信问题。DenseHybrid[17]则采用混合异常检测策略获取异常评分。
在语义分割领域的异常检测领域,一个显著趋势正在显现:模型正通过重新训练来提升识别异常物体的敏感度[7,12]。训练数据源自异常暴露(OE,Outlier
Exposure)流程,该流程通过将特定异常物体融入正常分布图像[23],从而增强模型对异常的鲁棒性。尽管这些现有异常检测模型的根基仍在于语义分割,但其输出格式与传统分割方法存在显著差异。不同于传统分割方法基于置信度生成掩码,这些异常检测方法会输出异常评分图作为结果。然而,使用异常分数图存在实际局限性,因为其在定位异常数据对象时的准确性不如掩码。
3.方法
我们采用一种简单高效的流程来解决语义分割中的异常检测问题。该方法突破了现有基于异常分数检测的局限性——传统方法主要输出像素级异常评分,虽然这些评分能预判像素是否属于异常对象,但要准确获取整个异常对象的分割掩膜却存在困难。相比之下,我们提出的S2M模型通过异常评分图生成框提示,这些提示能有效指示异常对象的存在。这些框提示作为输入,与原始图像共同输入到可提示分割框架中,最终生成异常对象的分割掩膜。该框架的训练流程如图3所示。
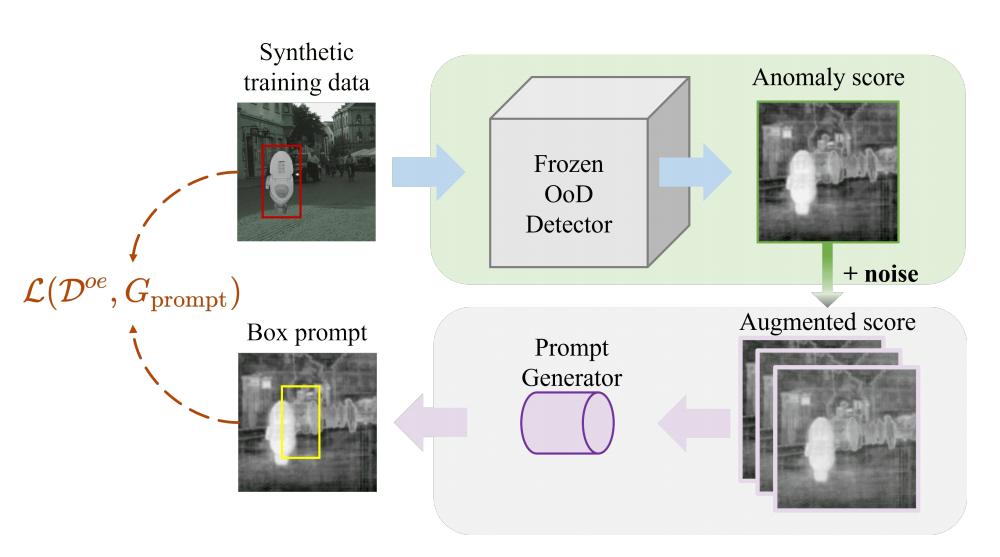
图3. 训练流程概览。我们冻结了OoD检测器,仅对prompt生成器进行训练。
3.1. 图像到异常分数
考虑一个标记为\(f(x;\theta)\)的分割网络,输入图像\({x}\in\mathbb{R}^{H\times
W\times3}\),其中W表示图像宽度,H表示图像高度。该网络为像素i生成的logit值可表示为\(L_{i}(x;\theta)\;=\;\left(f_{i}^{1}(x;\theta),f_{i}^{2}(x;\theta),\ldots,f_{i}^{C}(x;\theta)\right)\),其中C代表总类别数。通过softmax函数对\(L_{i}(x;\theta)\)进行归一化处理后得到\(P_{i}(x;\theta)\)。基于模型输出可计算异常分数\(S_{i}(x;\theta)\)。
一种基于香农熵[11,15]计算的异常分数定义如下:
\[H_{i}(x,\theta)=-\sum_{c\in
C}P_{i}^{c}(x;\theta)\log_{2}P_{i}^{c}(x;\theta)\]
熵值越高,说明分割模型对像素i的预测存在不确定性,表明该像素更可能属于OoD对象。近期,
PEBAL [46]提出采用基于能量的方法计算异常分数。 \[E_{i}(x;f)=-T\cdot\sum_{c\in
C}e^{f_{i}^{c}(x)/T}\]
其中T为温度参数。如前所述,虽然异常分数能判断单个像素是否属于OoD对象,但要获取整个OoD对象的掩膜却颇具挑战。
3.2. 异常评分与框提示
虽然直接从异常分数生成掩膜存在挑战,但这些分数本身仍能有效指示异常对象的位置。例如,当某个区域的像素异常分数较高时,很可能就存在异常对象。另一方面,语义分割领域涌现出的大规模模型——这些模型能根据给定提示生成精准的分割掩膜,标志着该领域近期取得重大突破。以Segment
Anything
Model(SAM)[26]为例,它能处理多种提示生成分割掩膜。这促使我们将异常分数转化为提示,让可提示分割模型生成异常对象的掩膜。
一种可行方案是直接采用异常分数较高的像素作为提示,这对应于点提示。然而,点提示因其高度特异性,存在显著误差风险。例如,由于其定位精度极高,点提示可能难以精确定位异常对象的中心,导致分割困难。即使使用多个点提示,实现对异常对象的全面覆盖仍存在挑战。图4显示,使用点提示进行异常对象分割可能导致生成不准确的掩膜。

图4. 相较于点提示,框提示能为异常对象提供更精准的分割效果。我们通过提取异常分数极端值对应位置生成点提示。可视化分析表明,框提示显著提升了模型对噪声的容忍度。我们采用所有生成的框提示构建异常对象的完整掩膜,确保整个对象被完全覆盖。
因此,我们提出开发能有效抵御异常分数噪声干扰的提示框方案。该方案可显著提升提示式分割模型对异常数据对象的精准识别能力,如图4所示。具体而言,我们采用目标检测器作为提示生成器,生成框提示作为提示分割模型的输入。由于现实世界中的异常数据集无法获取,我们提出通过异常暴露生成的数据集来训练提示生成器。
3.3.异常值暴露
异常暴露(OE)在语义分割的异常检测中应用广泛。例如, RPL [32]
采用合成训练数据集训练异常检测器。基于此,我们提出利用现有数据集合成异常检测数据集,用于训练提示生成器。
特别地,假设我们有一个内部数据集\({\mathcal D}_{in}=\{(x_{i}^{i n},{y_{i}^{i
n}})\}_{i}^{\|{\mathcal D}_{in}\|}\),其中\(x^{i n}\ \in\ \mathcal{X}\ \subset\
\mathbb{R}^{H\times W\times3}\)代表输入图像,\(y^{i n}\ \in\ \mathcal{Y}^{i n}\ \subset\
{\{0,1\}}^{H\times
W}\)是包含C个分布类别的分割图。同理,异常值数据集定义为\({\mathcal
D}_{out}=\{(x_{i}^{out},{y_{i}^{out}})\}_{i}^{\|{\mathcal
D}_{out}\|}\)其中\(x^{out}\ \in\
\mathcal{X}\),\(y^{out}\ \in\
\mathcal{Y}^{out}\ \subset\ {\{0,1\}}^{H\times
W}\)表示像素级掩码标签,其中类别1专用于异常类像素。需要注意的是,\({\mathcal D}_{in}\)和\({\mathcal
D}_{out}\)不包含重叠的类别。
在OE过程中,首先将转换函数T应用于OoD对象掩码\(y^{out}\),对OoD图像及其对应掩码进行随机重缩放。随后将图像和掩码裁剪或补全至非分布图像的尺寸。OE过程的数学表达式如下:
\[x^{o e}=\left(1-T\left(y^{o u
t}\right)\right)\odot x^{i n}+T\left(y^{o u t}\right)\odot x^{o u
t}\] 同样,我们还使用转换函数T对异常值掩码标签进行转换: \[y^{o e}=T\left(y^{o u t}\right)\]
OE流程将生成合成的OoD数据集\({\mathcal
D}_{oe}=\{(x_{i}^{oe},{y_{i}^{oe}})\}_{i}^{\|{\mathcal
D}_{oe}\|}\),用于训练提示生成器。
3.4.生成器训练提示
训练提示生成器的初始步骤是将掩码标签\(y^{oe}\)转换为提示标签。具体而言,通过寻找能完全包含所有被遮挡像素的最小矩形区域坐标,使用转换函数\(T_{box}\)将\(y^{oe}\)生成框提示\(B_{prompt}\)。 \[B_{p r o m p t}^{y^{o c}}=T_{b o x}\left(y^{o
e}\right)\]
接下来,为获取合成训练图像的异常分数,我们采用主流的OoD检测方法\(f_{ood}\)。对于每张合成图像\(x^{oe}\),其异常分数可通过以下公式计算:
\[S_{a n o m a l y}^{x^{o
e}}=f_{ood}(x^{oe})\]
基于这些异常分数和边界框提示,我们继续训练提示生成器\(G_{prompt}\)。训练目标是让\(G_{prompt}\)能够处理异常分数并生成对应的边界框提示。损失函数可表示为:
\[\mathcal{L}({\mathcal D}^{o
e},G_{\mathrm{prompt}})=\sum_{x^{o e}\in\mathcal D^{o
e}}\ell\left(G_{\mathrm{prompt}}(S_{\mathrm{anomaly}}^{x^{o
e}}),B_{\mathrm{prompt}}^{y^{o e}}\right)\] 其中\(\ell\)
是损失函数,用于量化生成提示与实际框提示之间的差异。通过最小化损失函数\(\mathcal{L}\),提示生成器可根据异常评分图生成精准的框提示。完整流程如图3所示。
在实验中,我们通过向异常分数添加随机噪声来进一步提升模型的鲁棒性。特别地,当异常分数值经历1%的随机波动时,模型表现最佳。这种增强策略不仅增强了模型对异常分数波动的适应能力,还显著提升了其在真实类外数据集上的泛化性能。
3.5.推理流程
推理阶段,输入图像会通过最先进的异常检测方法进行处理,生成异常分数图。该图随后输入提示生成器,生成标注潜在异常对象位置的边界框提示。接着,我们采用可提示分割模型,该模型同时接收提示和原始图像作为输入,最终生成如图5所示的异常对象掩膜。
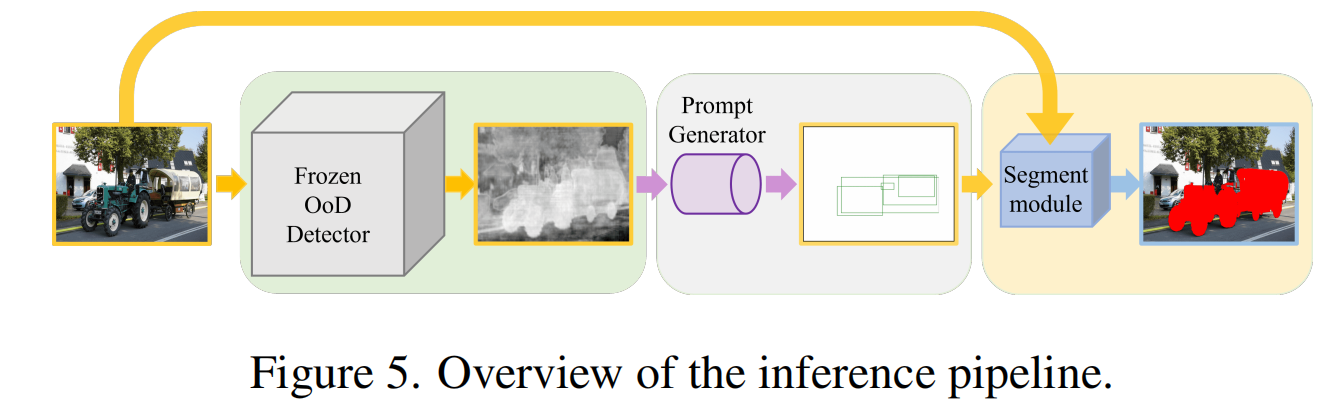
由于异常分数较高的区域可能呈现碎片化特征,提示生成器可能会生成多个分割框提示。此时,我们将所有提示输入到提示分割模型中,并将所有生成的掩膜区域合并后作为最终结果。
4.实验
5.总结
我们提出S2M框架,这是一种简单高效的语义分割异常检测方法。该框架能将各类异常分数图转换为分割掩膜,精准识别异常对象。S2M具有通用性,可整合多种异常检测器的分数数据。大量实验表明,该方法在多个主流异常检测基准数据集上,无论从组件级指标还是像素级指标来看,均优于现有最先进检测技术。