Text-Driven Traffic Anomaly Detection With Temporal High-Frequency Modeling in Driving Videos
Text-Driven Traffic Anomaly Detection With Temporal High-Frequency
Modeling in Driving Videos
Rongqin Liang , Student Member, IEEE,
Yuanman Li , Senior Member, IEEE, Jiantao Zhou , Senior Member, IEEE,
and Xia Li , Member, IEEE
摘要
驾驶视频中的交通异常检测(TAD)对于确保自动驾驶和高级驾驶辅助系统的安全性至关重要。以往的单阶段TAD方法主要依赖于帧预测,这使得它们容易受到仪表板摄像头快速移动引起的动态背景干扰。虽然两阶段TAD方法似乎是一种自然的解决方案,通过使用感知算法预先提取与背景无关的特征(如边界框和光流)来减轻此类干扰,但它们容易受到第一阶段感知算法性能的影响,并可能导致误差传播。在本文中,我们介绍了一种新的单阶段方法 TTHF ,该方法通过文本提示对齐视频片段,为交通异常检测提供了新的视角。与以往方法不同,我们的监督信号来源于语言而非正交独热向量,从而提供了更全面的表征。此外,关于视觉表征,我们提出在时域中建模驾驶视频的高频特性。这种建模捕捉了驾驶场景的动态变化,增强了对驾驶行为的感知,并显著提高了交通异常的检测效果。此外,为了更好地感知各种类型的交通异常,我们精心设计了一种注意力异常聚焦机制,该机制通过视觉和语言引导模型自适应地关注感兴趣的视觉上下文,从而促进交通异常的检测。研究表明,我们提出的 TTHF 取得了令人鼓舞的性能,在DoTA数据集上比最先进的竞争对手高出5.4%的AUC,并在DADA数据集上实现了高度泛化。
1.引言
在驾驶视频的交通异常检测领域,我们强调除了视觉特征分析外,从时间维度刻画驾驶场景的动态变化对识别异常驾驶行为具有显著优势。例如车辆碰撞或失控等交通事件,往往会导致驾驶场景发生剧烈且快速的改变。因此,如何有效刻画驾驶场景的动态变化,成为驾驶视频交通异常检测的核心技术。
此外,由于不同类型的交通异常具有独特特征,若对整个驾驶场景进行简单编码,可能会降低驾驶事件的可识别性,进而影响对多样化交通异常的检测。例如,涉及本车的交通异常通常伴随仪表盘摄像头的全局抖动,而涉及非本车的异常则往往导致驾驶场景中的局部异常。因此,如何更有效地感知各类交通异常,对交通异常检测至关重要。
在本工作中,我们提出了一种新的交通异常检测方法:文本驱动的交通异常检测与时间高频建模(TTHF),如图2所示。为了全面呈现驾驶视频,我们的核心理念不仅是捕捉空间视觉上下文,还要强调驾驶场景中动态变化的描绘,从而增强驾驶视频的视觉表现。具体来说,我们首先利用CLIP预训练的视觉编码器,该编码器具有丰富的视觉语言语义先验知识,来编码驾驶视频的视觉上下文。然后,为了捕捉驾驶场景中的动态变化,我们创新性地引入了时间高频建模(THFM),以获取驾驶视频沿时间维度的高频表征。随后,将视觉上下文和时间高频表征融合,以增强驾驶视频的整体视觉表现。为了更好地感知各种类型的交通异常,我们提出了一种注意力异常聚焦机制(AAFM),引导模型自适应地从视觉和语言两个方面关注感兴趣的视觉上下文,从而促进交通异常的检测。
研究表明,我们提出的
TTHF
模型在DoTA数据集[9]上表现出色,比最先进的竞争对手高出5.4%的AUC。此外,未经任何微调,
TTHF
在DADA数据集[23]上的AUC表现证明了其泛化能力。本工作的主要贡献可总结如下:
- 我们提出一种简单高效的单阶段交通异常检测方法,通过将驾驶视频的视觉语义与匹配的文本语义对齐来识别交通异常。与以往的交通异常检测方法不同,本方法中的监督信号源自文本,从而在高维空间中提供更全面的表征。
2. 我们着重于在时域对驾驶视频进行高频建模。与以往仅沿时间维度聚合视觉上下文的方法不同,我们更强调时域高频建模。这使我们能够表征驾驶场景随时间的动态变化,从而显著提升交通异常检测性能。
3. 我们进一步提出一种注意力异常聚焦机制,以增强对各类交通异常的感知能力。该机制通过视觉和语言双重方式引导模型,自适应聚焦于目标视觉上下文,从而促进交通异常的检测。
4. 在公开基准数据集上的综合实验结果证明了所提出方法的优越性和鲁棒性。与现有的最先进方法相比,所提出的 TTHF 在DoTA数据集上将AUC提高了5.4%,并且在DADA数据集上无需任何微调即可达到最先进AUC。
3.提出的方法:TTHF
在本节中,我们主要介绍提出的 TTHF 框架。首先,我们描述 TTHF 的整体框架。然后,我们解释 TTHF 中的两个关键模块,即时间高频建模(THFM,temporal High-Frequency Modeling)和注意力异常聚焦机制(AAFM,attentive anomaly focusing mechanism)。此外,我们描述了用于视频文本对跨模态学习的对比学习策略,最后展示如何在我们的 TTHF 中进行交通异常检测。
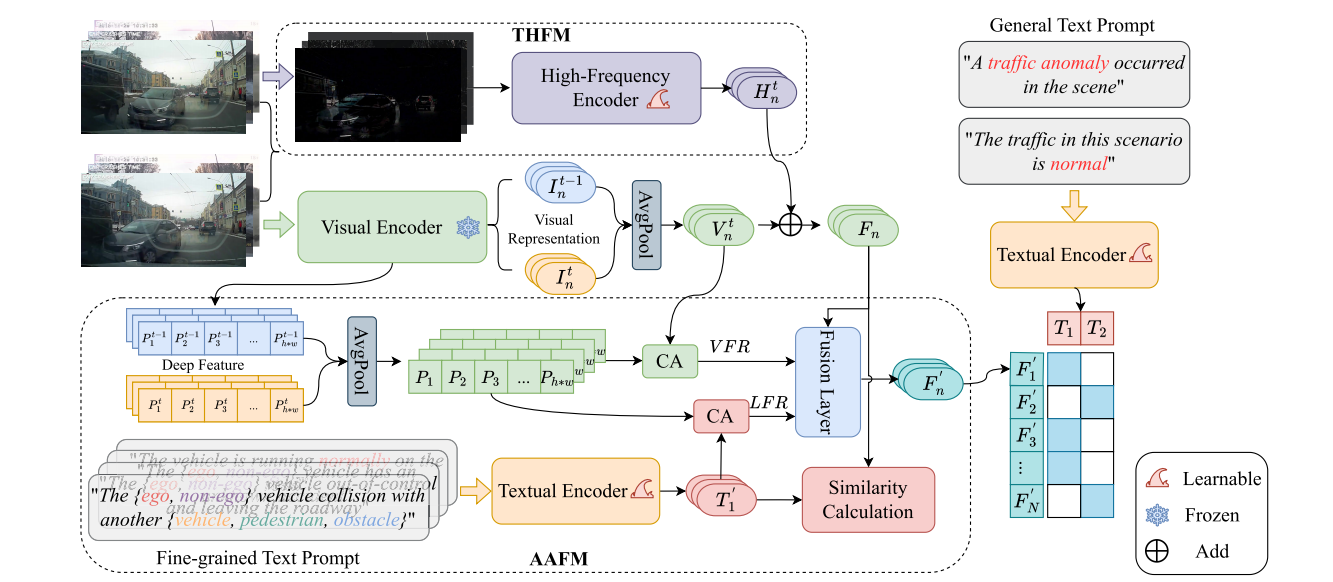
图2. 我们提出的 TTHF 框架概览。这是一个类似于CLIP的交通异常检测框架。在此框架中,我们首先应用视觉编码器提取驾驶视频片段的视觉表征。然后,我们提出时间高频建模(THFM)来表征驾驶场景的动态变化,从而构建更全面的驾驶视频表征。最后,我们引入注意力异常聚焦机制(AAFM)以增强对各种类型交通异常的感知。此外,为了简洁起见,我们将交叉注意力表示为CA,视觉聚焦表征为VFR,语言聚焦表征为 LFR 。
A. 我们的TTHF 框架概述
TTHF
的整体框架如图2所示。该框架采用类似CLIP的双流架构进行交通异常检测。在视觉上下文表征方面,大量研究[49]
[50]
[51]已证实CLIP具备强大的视觉-语言先验知识基础。利用这种积累的语义知识进行驾驶视频异常检测,有助于感知和理解驾驶行为。因此,我们建议采用CLIP的预训练视觉编码器,从连续两帧的驾驶视频片段中提取视觉表征。在获得帧表征后,我们沿时间维度采用平均池化技术(如先前研究[19]
[20]
[21]所述),将这些表征聚合以表征视频片段的视觉上下文。对于文本表征,我们首先将正常和异常交通事件描述为文本提示(即表I中的a1和a2),然后应用CLIP中的预训练文本编码器提取文本表征。
直观来说,在提取驾驶视频片段的视觉和文本表征后,我们可以直接利用对比学习将它们对齐用于交通异常检测。然而在我们的任务中,仅通过视觉上下文建模视觉表征不足以捕捉驾驶场景中的动态变化。因此,我们引入了时序高频建模(THFM)来表征动态变化,并为驾驶视频片段提供更全面的表征。此外,为了更好地感知各种类型的交通异常,我们进一步提出了一种注意力异常聚焦机制(AAFM),以自适应地关注驾驶场景中感兴趣的视觉上下文,从而促进交通异常的检测。在接下来的部分中,我们将详细介绍这两个关键模块。
B. 时间高频建模(THFM)
视频-文本对齐与图像-文本对齐的不同之处在于需要考虑时间特性。许多方法[19]、[20]、[21]已经有效地利用了CLIP来解决视频领域的下游任务。这些方法在时间域中采用的建模策略包括各种技术,如平均池化、Conv1D、
LSTM
和Transformer。这些策略主要强调沿时间维度从不同的视频帧中聚合视觉上下文。然而,对于驾驶视频中的异常检测任务,我们认为不仅视觉上下文,驾驶场景中的时间动态变化在建模驾驶行为中也具有重要意义。例如,碰撞或车辆失控通常会在短时间内引起驾驶场景的显著变化。因此,在我们的工作中,我们提出从两个方面建模驾驶视频的视觉表示,即视频帧在空间域中的视觉上下文和驾驶场景在时间域中的动态变化。考虑到驾驶视频在时间域中的高频反映了驾驶场景的动态变化。为了说明这一点,我们在图4中展示了几个案例。基于上述观察,我们引入了时间高频建模(THFM),以增强驾驶视频在时空域中的视觉表示。
我们的核心理念在于利用驱动视频时域中呈现的高频信号来表征动态变化。
融合视觉表征Fn不仅建模了驾驶视频片段的视觉上下文,还表征了时间维度上的动态变化,这对感知和理解驾驶行为具有重要意义。
C. 注意力异常聚焦机制
不同类型的交通异常往往具有显著特征。例如,涉及本车的异常通常伴随仪表盘摄像头的全局抖动,而涉及非本车的异常则通常导致驾驶场景局部区域的异常。盲目编码整个驾驶场景可能降低驾驶事件的可区分性,阻碍各类交通异常的检测能力。因此,自适应聚焦于目标视觉上下文对于感知不同类型的交通异常至关重要。
在我们的工作中,我们提出了一种注意力异常聚焦机制(AAFM)。其基本思想是将视觉上下文从视觉和语言上解耦,以引导模型自适应地聚焦于感兴趣的视觉内容。具体来说,我们精心设计了两种聚焦策略:视觉聚焦策略(VFS)和语言聚焦策略(LFS)。前者利用具有全局上下文的视觉表征,专注于最相关的语义视觉上下文;后者则通过语言的引导,自适应地聚焦于与文本提示最相关的视觉上下文。
1)视觉聚焦策略(VFS):
实际上,空间视觉表征本身就能捕捉全局上下文。通过将视觉表征的注意力集中在驾驶场景中各个区域的深层特征上,可以聚焦于最具语义相关性的视觉内容。具体而言,如图2所示,我们通过在空间视觉上下文表征Vn
t与视频片段的深度特征之间应用交叉注意力机制(CA),对目标深度特征进行聚焦与加权,其表达式可表示为:
\[V F R_{n}=s o f t m a x\Biggl({\frac{\cal
Q}\left(V_{n}^{\prime}\right)\cdot
K^{\textsf{T}}\left(P\right)}{c}\Biggr)\cdot V\left(P\right),\]
其中 Q、K 和 V 是线性变换,P ∈ R h∗w×C
是视频片段的深度特征图,(h,w)表示特征图的尺寸,c
是缩放因子,指的是特征维度的平方根。需要注意的是,对于基于变压器的视觉编码器,Vn
t 由类别标记表示,而 P 由补丁标记表示。V F Rn ∈ R 1×C 表示第 n
个视频片段的视觉聚焦表示。由于空间视觉表示编码了全局上下文,关注其最相关的视觉内容有助于引导模型感知驾驶场景的语义。如图
3(b) 所示,我们的 VFS
可以自适应地聚焦于驾驶场景中的关键场景语义。这种注意力有助于检测涉及自车的交通异常,特别是自车失控的情况(图
3 中的案例 1)。
2)语言聚焦策略(LFS):
直观来说,细粒度文本提示明确界定了交通事件中的主体、客体和交通类型。与通用文本提示(如表I中a1和a2所列)不同,使用细粒度文本提示有助于引导模型关注相关的视觉上下文,从而提高对各种交通异常的理解。因此,为了促进模型对相关视觉上下文的自适应感知,我们进一步设计了一种语言聚焦策略。核心思想是利用精心设计的细粒度文本提示(如表I中b1至b4所列)引导模型自适应地关注感兴趣的视觉上下文,从而增强对交通异常的理解。
具体而言,我们首先根据事件类型将交通事件划分为四类。其次,针对每类事件,我们进一步根据涉及主体(即自我车辆或非自我车辆)和物体(即车辆、行人或障碍物)进行细分。最终,我们定义了11种细粒度文本提示类型,如表I中b1至b4所示。需要说明的是,实验中使用的DoTA数据集标注了9种交通异常类型(详见表II),每种异常类型均包含自我车辆相关和非自我车辆相关的异常情况。
D. 对比学习策略与推理过程
在本节中,我们将介绍所提出的跨模态学习 TTHF 框架的对比学习策略,并展示如何进行交通异常检测。
推理过程与训练过程类似。对于第i个测试驾驶视频片段,我们的 TTHF 首先提取视觉表征Fi和增强视觉表征Fi′。对于文本提示,文本编码器构建11个细粒度文本表征T′ = {T1′,T2′ ,... ,T11′}和2个通用文本表征T = {T1,T2}。然后分别计算Fi与T′以及Fi′与T之间的余弦相似度。
5.结论
本文提出了一种精确的单阶段TAD框架。该框架首次引入视觉-文本对齐技术,用于解决驾驶视频中的交通异常检测任务。值得注意的是,我们验证了在时域建模驾驶视频的高频特征有助于表征驾驶场景的动态变化并增强视觉表征,从而显著提升交通异常检测效果。此外,实验结果表明,所提出的注意力异常聚焦机制确实能有效引导模型自适应聚焦于目标视觉内容,从而增强对不同类型交通异常的感知能力。尽管大量的实验已经证明,所提出的 TTHF 明显优于最先进的竞争对手,但仍需要更多的努力来准确检测更具挑战性的轻微交通异常。