TruFor:Leveraging all-round clues for trustworthy image forgery detection and localization

TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization
Fabrizio Guillaro1 ,Davide Cozzolino1 ,Avneesh Sud2 ,Nicholas Dufour2 ,Luisa Verdoliva1
1University Federico II of Naples
2Google Research
![]()
摘要
本文提出TruFor取证框架,可应用于从传统廉价伪造到基于深度学习的新型图像篡改技术。该框架通过基于Transformer的融合架构,同时提取高阶特征与低阶特征:前者整合RGB图像与自适应学习的噪声敏感指纹,后者则通过仅使用真实数据进行自监督训练,精准捕捉相机内外部处理产生的伪影特征。系统通过检测原始图像中规律性特征的异常偏离,实现对伪造图像的有效识别。通过异常检测机制,该方法能有效识别各类局部篡改行为,确保结果具有普适性。除像素级定位图和全图像完整性评分外,我们还生成了可靠性评估图,精准标注定位预测可能出现误判的区域。这一特性在取证应用中尤为重要,既能减少误报风险,又支持大规模分析。基于多个数据集的大量实验表明,我们的方法在检测和定位廉价伪造与深度伪造篡改方面表现优异,其准确率已超越现有最先进方案。代码可在https://grip-unina.github.io/TruFor/上公开获取。
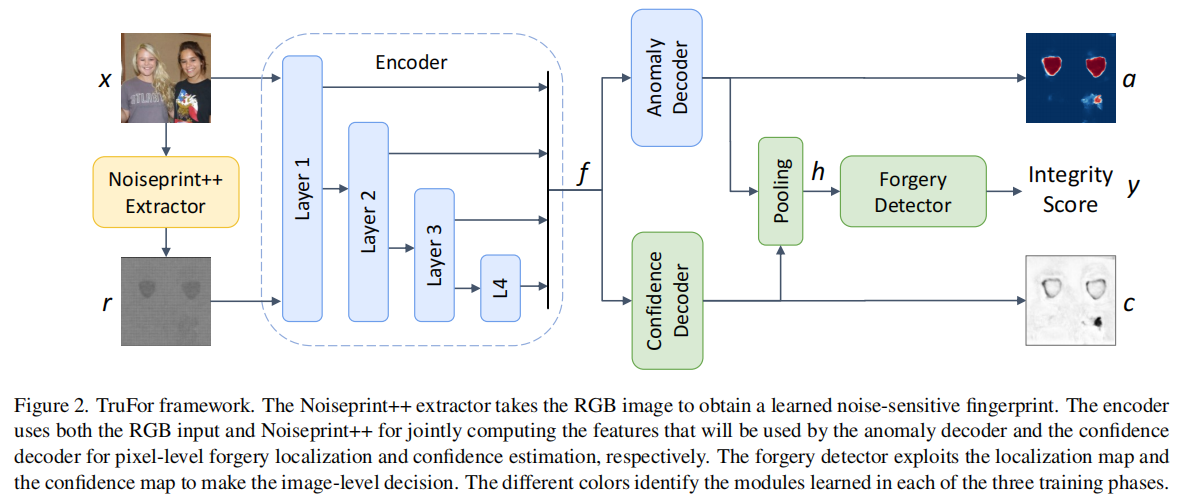
4.结果
4.1.实验设置
训练
我们的方法包含三个独立的训练步骤。首先,我们使用两个热门图片分享网站——Flickr(www.flickr.com)和DPReview(www.dpreview.com)上公开的大量原始图像数据集来训练Noiseprint++提取器。该数据集包含来自43个品牌的1475款不同相机型号(每款8至92张图像)拍摄的24,757张原始图像。接着,我们采用与CAT-Net
v2
[24]提出的相同数据集(包含原始图像、伪造图像及其对应真实标签),训练异常定位网络的编码器和解码器。最后,基于同一数据集,我们训练置信度图解码器和伪造检测器。更多数据集详情可参见补充材料。
测试
我们通过七个公开数据集和一个基于扩散模型开发的本地处理数据集对模型进行了基准测试。具体而言,我们采用了文献中广泛使用的CASIA
v1 [15]、Coverage [40]、Columbia [20]、NIST16 [19]、DSO-1 [13]和VIPP
[7]等数据集,这些数据集包含剪辑、复制移动和修复等低成本伪造操作。总体而言,这些数据集共包含1530张伪造图像和1412张真实图像。此外,我们还加入了OpenForensics
[26]——一个使用GAN模型生成的面部伪造大数据集,并从中抽取了2000张图像;同时引入了CocoGlide数据集,其中包含512张由GLIDE扩散模型(基于COCO
2017验证集中的图像生成)生成的图像。
指标
与以往大多数研究类似,我们在像素级评估中采用F1指标,并同时展示最佳阈值和默认0.5阈值的对比结果。而在图像级分析中,我们改用无需设定决策阈值的AUC指标,以及综合考虑误报与漏检的平衡准确率指标——此时阈值同样被重新设定为0.5。
4.2.最新技术水平比较
为确保公平比较,我们仅选取在线公开代码和/或预训练模型的方法,并在选定的测试数据集上进行验证。此外,为避免偏差,我们仅纳入在与测试数据集不重叠的数据集上训练的方法。最终纳入的模型方法包括:基于JPEG伪影的ADQ [6]、利用噪声伪影的Splicebuster [10];以及11种深度学习方法:EXIF自洽性[22]、约束R-CNN [44]、RRU-Net [5]、ManTraNet [42]、SPAN [21]、AdaCFA [2]、端到端[31]、CAT-Net v2 [24]、IF-OSN [41]、MVSS [8]、PSCC-Net [29]、Noiseprint [12]。这些方法的简要概述详见表3。

定位结果
在表1中我们展示了像素级定位性能。
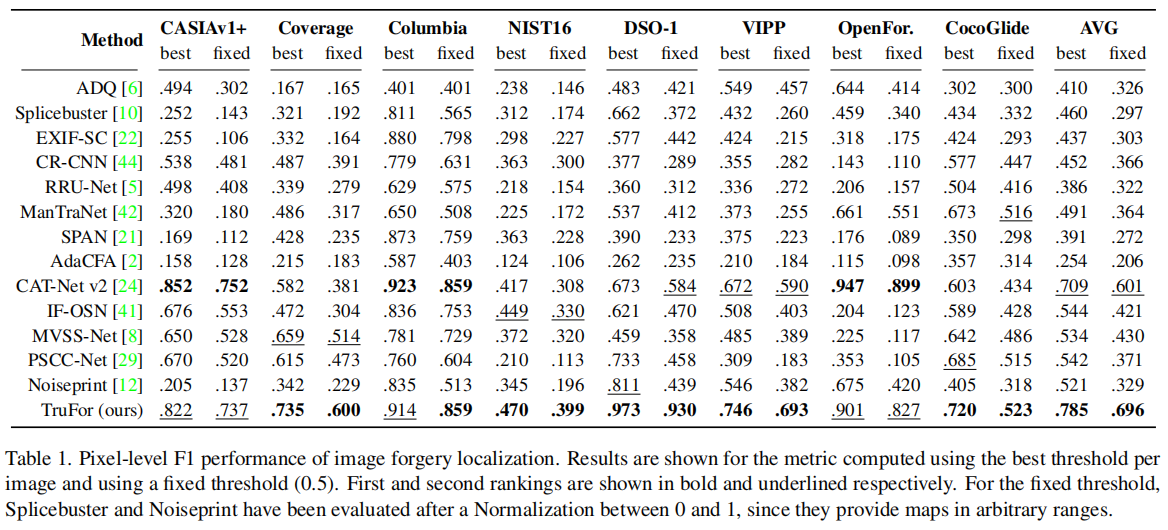
我们的方法平均F1值表现最佳,在所有测试数据集上均位列第一或第二,充分证明了其在各类操作场景下的卓越泛化能力。事实上,该方法在OpenForensics(基于生成对抗网络的局部操作)和CocoGlide(扩散模型驱动的局部操作)等场景中同样表现出色——除CAT-Net v2外,其他多数方法在此类任务中均遭遇惨败。得益于采用Noiseprint++算法(基于数字历史记录的训练方法),我们的方法在所有测试数据集上始终保持优异表现。