Video_Source_Characterization_Using_Encoding_and_Encapsulation_Characteristics
Video Source Characterization Using Encoding and Encapsulation Characteristics
Enes Altinisik , Hüsrev Taha Sencar , Senior Member, IEEE, and Diram Tabaa
摘要
我们提出采用视频编码设置进行源识别,并创新性地将视频的编码与封装特性融入其中。为此,我们开发了整体文件元数据的联合表征方法,并将其与双层级分类体系相结合。在第一层级中,我们的方法通过多个抽象维度对视频进行元类划分,这些维度表征了文件元数据的高层次结构特征。接下来是针对构成每个元类的更细致分类。该方法在结合四个公开视频数据集采集的2万余段视频上进行了评估。测试结果显示,在正确识别119个视频类别中的12个类别时,达到了91%的平衡准确率。这比基于视频文件封装特征的传统方法提升了6.5个百分点。对大量未标注视频数据集的分析也验证了我们方法的有效性。为进一步展示编码参数的通用性,我们考虑了部分视频文件的归属问题——这些文件缺乏元数据信息。研究结果表明,即使在这种固有于取证文件恢复的有限场景中,通过从编码视频数据中估算出的21组编码参数子集,仍能实现57%的识别准确率。
结果
我们现对所提出的信源识别方法进行有效性验证。本研究采用闭集识别场景进行评估,通过整合VISION、ACID、SOCRatES和EVA-7K四个数据集构建大规模视频库。前三个数据集包含智能手机及数码相机拍摄的原始视频,最后一个数据集则汇集了从多个社交媒体平台获取并经过多种编辑工具处理的多来源视频素材。最终形成的数据集包含来自28个品牌的112款摄像机型号、3种编辑工具及4个社交媒体平台的20,153段视频,每类视频数量介于10至1,400条之间。分析表明,除涉及八款摄像机型号的视频外,其余视频均采用H.264-MP4格式编码。其中五款摄像机支持H.264编码,一款采用MP4文件容器格式,另外两款则不支持这两种格式。鉴于数据集存在显著的类别不平衡问题,我们在性能评估中采用了平衡准确率指标,该指标通过统一标准来衡量各摄像机型号的识别效果。
A.编码和封装特性的比较
我们首先分别量化编码与封装特性单独及联合提供的可区分性水平。在评估过程中,我们采用了与先前研究[24] [26]相似的扁平化分类方法。为此,我们通过两种文件元数据树形表示法来确定可实现的识别准确率,并将其作为基准。第一种是基于根到叶路径描述的稀疏向量表示法,该方法结合了两个特征向量[24]:一个使用仅含字段名称的路径条目无序列表生成,另一个则包含字段和值的无序列表(见图1)。第二种是文献[26]中提出的轨迹与(字段)类型感知表示法,未进行特征选择且未采用基于LDA的特征降维技术。使用该表示法时,所有编解码器参数均被视为非分类变量。为评估元数据解析器的影响,我们使用两个公开的解析库[34] [38]为所有视频生成文件元数据树。随后利用特征向量训练决策树(DT)分类器,并采用平衡类别权重进行训练6。
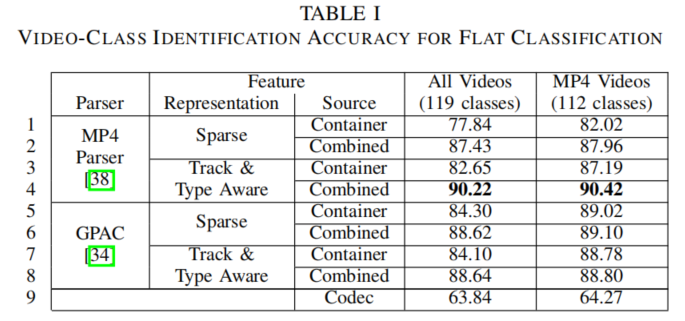
表I展示了经过100次五折交叉验证获得的平衡准确率数据,通过多次验证有效降低了抽样偏差。第一列标注了解析MP4元数据所用的库,第二列说明了将文件元数据树转化为特征向量的方法,第三列则指明了元数据来源——即基于容器、编解码器或两者的组合。第四列呈现了在识别119类视频(共20,153个视频样本)时获得的平衡准确率结果。最后列展示了仅使用MP4格式视频进行测试的结果,这使得综合数据集缩减至112类(含18,456个视频样本)。
实验结果表明,单独对比时编解码器参数(第9行)的区分度低于MP4文件元数据(第1、3、5、7行)。这主要归因于编解码器参数维度较低,而MP4文件元数据包含丰富信息。但当两者结合使用时,两种信息源的互补特性在所有测试场景中都展现出最佳准确率(第2、4、6、8行)。具体而言,在整体数据集中,无论是采用稀疏特征[24]还是轨道与类型感知特征[26]对容器特征进行表征,最高平衡准确率达到84.3%(第5行)。而在组合使用场景下,平衡准确率提升至90.22%(第4行),准确率提高6个百分点。即使仅分析MP4格式视频,分类准确率也从89.02%(第5行)提升至90.42%(第4行),增幅达1.4%。总体而言,这些结果表明视频编码方式能显著增强视频文件的识别能力。
我们的研究结果表明,相较于稀疏表示,更紧凑的轨道特征和类型感知特征表示通常能获得更好的性能表现。进一步分析显示,两种解析器提取的元数据确实存在差异。相比之下,GPAC解析器在两种特征表示方式上都更具优势。但在综合应用场景中,MP4解析器的表现最为出色。这一现象可能与GPAC解析器提取的SPS和PPS字符串(MP4解析器未考虑这些参数)结合单独参数值的做法有关,这种处理方式可能导致决策树分类器产生混淆。
B.双层分级分类法
在第一层,分层方法根据高级结构属性将文件元数据树归类为元类。在此方面,文件元数据树的LDP图嵌入结果为1280位表示,节点标记图嵌入结果为3K位表示,而树哈希方法则产生256位索引值。在第二层,使用跟踪和类型感知表示将每个元类中的文件元数据树映射到特征向量,并为每个元类构建一个DT分类器。在训练过程中,每个类别都会根据其在整体训练集中的权重进行加权处理。为充分发挥两种解析器的优势,我们采用GPAC作为第一层级解析器,MP4解析器作为第二层级解析器——后者在平面分类任务中表现略胜一筹。测试系统时,若无法为特定文件元数据树识别出对应的元类型,则将其归入未知类别。这些视频将使用表I(第4行)中最佳模型进行分类。
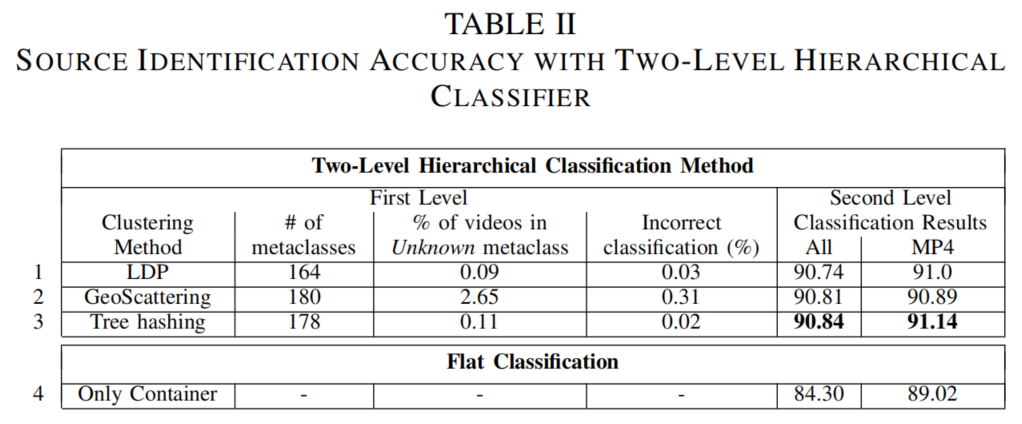
表II展示了五折交叉验证的结果,这些结果基于对训练集和测试集进行50次随机化处理后的平均值(第1-3行)。具体来说,在每次运行中,我们使用80%的视频数据来识别元类别并训练多个决策树分类器,而剩余20%的数据则用于评估整个系统的平衡识别准确率。表格首列显示了第一层文件元数据树聚类所采用的方法,随后三列则呈现了在完整数据集上获得的第一层级分类结果。第二列展示了各抽象层级生成的元类总数。三种抽象方式产生的元类数量相对较少,这验证了我们的直觉判断:文件元数据树在结构上高度相似,不同视频间的差异并不显著。第三列显示的未知类别占比进一步证明,每个元类对应的结构都具有高度稳定性。研究发现,除第二个抽象层级外,平均仅有0.1%的视频被归入未知类别。(在聚类地理散射嵌入时,我们采用3.5的欧氏距离作为阈值来判定视频是否属于未知类别。)第四列数据显示,将文件元数据树错误归类到第一级超类的情况发生率极低,且所有案例中该误差值均处于极低水平。
在第二层级通过三种抽象方法获得的视频源识别准确率数据,分别展示在最后两列中,包含完整数据集(119个类别)和精简版本(112个类别)。总体而言,三种抽象方法的表现相近,但第一层级采用树哈希算法时效果最佳。与采用容器特征平面分类法(如第4行所示)获得的最佳结果相比,我们提出的方法在整体数据集上实现了平衡准确率6.5%的提升,从84.3%增至90.8%。当仅考虑MP4视频时,准确率提升幅度为2.1%,从89.02%提高到91.14%。
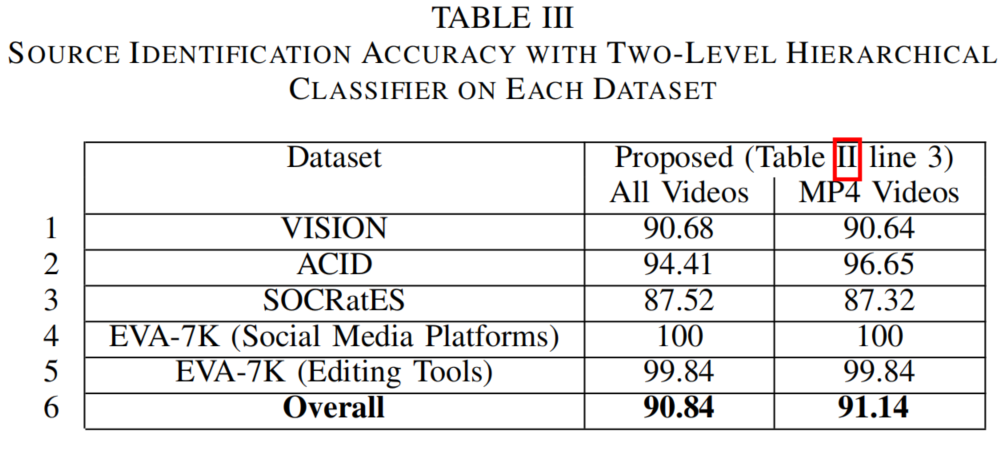
我们还通过在不同数据集上单独训练和测试模型的方式对方法进行了评估。表III展示了VISION、ACID、SOCRatES和EVA-7K四个数据集对应的识别准确率。其中,EVA-7K数据集被进一步划分为两个子集,以便更好地捕捉视频重新编码和封装过程中编辑工具及社交媒体平台对文件元数据的影响。结果显示,在四个数据集中,EVA-7K和ACID对视频类别识别的挑战性最低。相比之下,SOCRatES被发现是最具挑战性的数据集。这主要归因于该数据集包含56个视频类别,其中38个类别仅包含10个样本,每个类别的平均样本量仅为16个。
C.可扩展性评估
关于我们的来源归因方法,一个关键问题是其在大量来源类别下的扩展性。为部分验证这一问题,我们创建了另一个数据集。为此,我们从公共视频分享网站lbry.com获取了92,603个视频——与其他主流视频分享平台不同,该网站默认不会对用户上传的视频进行转码和重新封装。我们通过迭代爬取主页上的推荐视频链接,从14,916个平台用户账户中收集了这些视频。可以合理推测,相较于包含20,000个视频的测试集,这个视频集合的来源更加多样化。然而,该视频集的一个重要局限在于缺乏来源类别标签(即摄像头型号和/或处理软件套件),因此无法验证其归因准确性。在缺乏此类信息的情况下,我们转而考察学习层级第一级遇到的元类数量以确定其扩展特性。同时,我们还研究了用于第二级分类的MP4文件容器特征数量的增长趋势。
在分析过程中,我们首先从所有视频中提取文件元数据树,并采用基于树哈希的抽象方法将其归类为元类别。结果显示共生成了2,027个元类别,较早期测试中的178个显著增加。其中规模最大的10个元类别包含约71,500个视频,最大单个元类别则包含约37,000个视频。我们推测这些视频集群可能是平台应用户要求进行转码处理的结果,因为其中包含6,173名用户的视频。其余各元类别均包含1-5,000个视频,表明某些编码和封装行为更为普遍。平均每个用户生成2.09个哈希值,8,019名用户仅生成一个(但未必唯一)哈希值,这说明用户间的编码与封装特征差异较小。此外,我们发现352个元类别与特定用户视频相关联,可能暗示存在罕见的摄像机型号、编辑工具或设置参数。
分类任务中使用的稀疏特征、轨迹特征及类型感知特征表示的维度变化,是另一个值得关注的问题。我们发现,根据解析器的选择和特征表示方式的不同,该视频数据集生成的特征向量规模可达3.5万至7万维。以综合测试数据集中视频特征向量(5千至1.1万维)为例,其维度增长幅度约为七倍。这种现象可归因于该视频集合包含更多视频源类别。由此可以推断,对于规模更大的数据集,采用平面分类方案将面临计算效率不足的困境。这进一步凸显了采用分层分类方法的必要性。
我们还通过重新排列30种相机型号拍摄的视频(依据其固件而非原始相机型号)重复了相同的来源归属测试。这产生了26个固件类别,对应的平衡准确率从90.6%(如表III所示)略微下降至89.5%。为深入理解这一现象,我们考察了特定型号和固件的相机是否能与所有其他相机(无论是同型号还是不同固件)区分开来。为此,我们选取了三款相机:iPhone 4和两款iPhone 4S机型——其中两款iPhone 4S使用不同的固件,而iPhone 4则与其中一款4S机型采用相同固件。在两种测试场景下(即型号级和固件级归属),这三款机型都能被完美区分。这本质上表明,视频的文件元数据特征可能同时受相机型号和固件版本的影响而发生变化。