文章总览 - 8
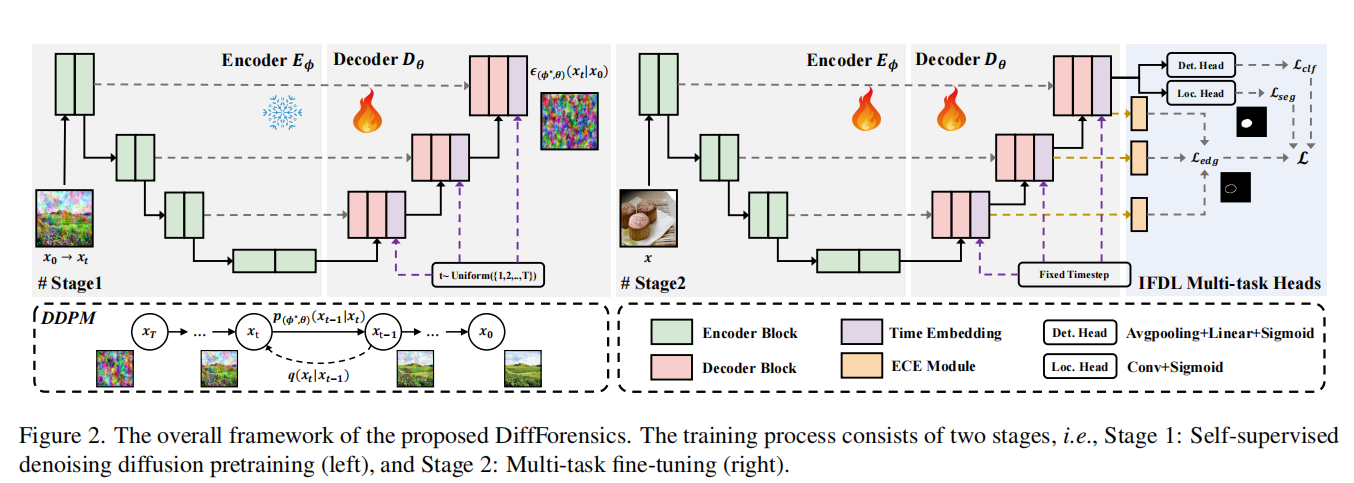
DiffForensics:Leveraging Diffusion Prior to Image Forgery Detection and Localization
发表于CVPR2024,两阶段的训练过程,该框架包括自监督去噪扩散的训练前阶段和多任务微调阶段,提出了一种新的边缘提示增强模块,该模块集成在多个尺度的解码器中,以增强被篡改的边缘痕迹从粗到细。
1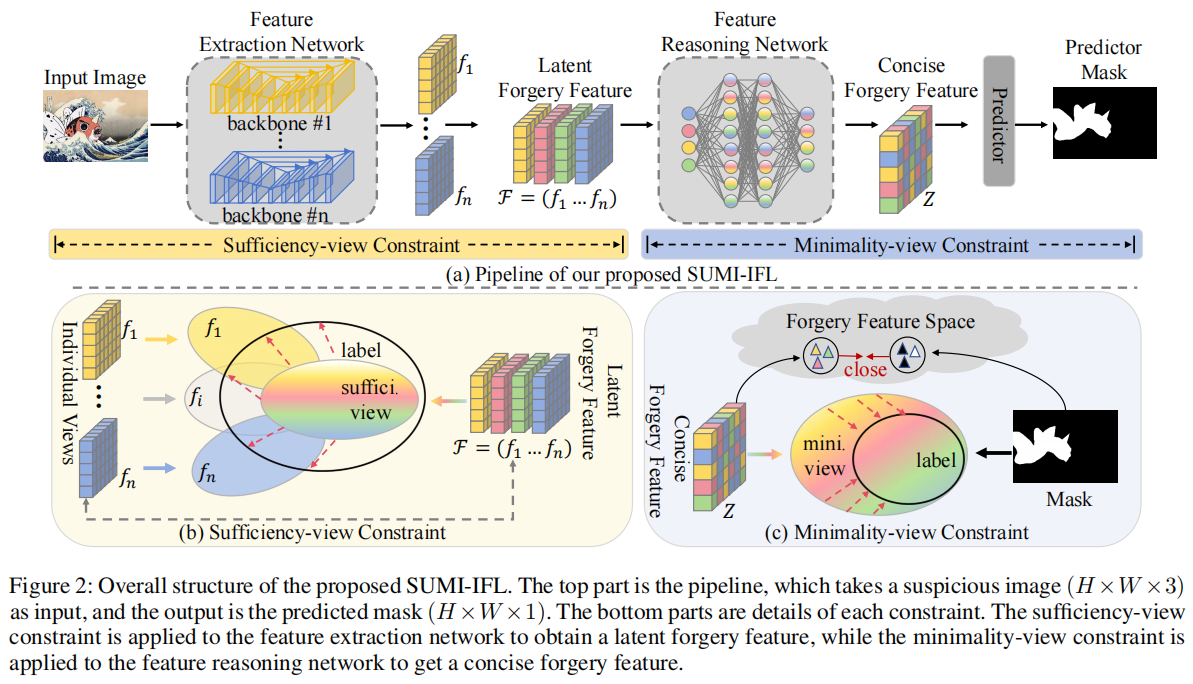
SUMI-IFL:An Information-Theoretic Framework for Image Forgery Localization with Sufficiency and Minimality Constraints
发表于aixiv,使用信息瓶颈理论完成图像篡改任务,没和NP++、IFL-VIT比较。
2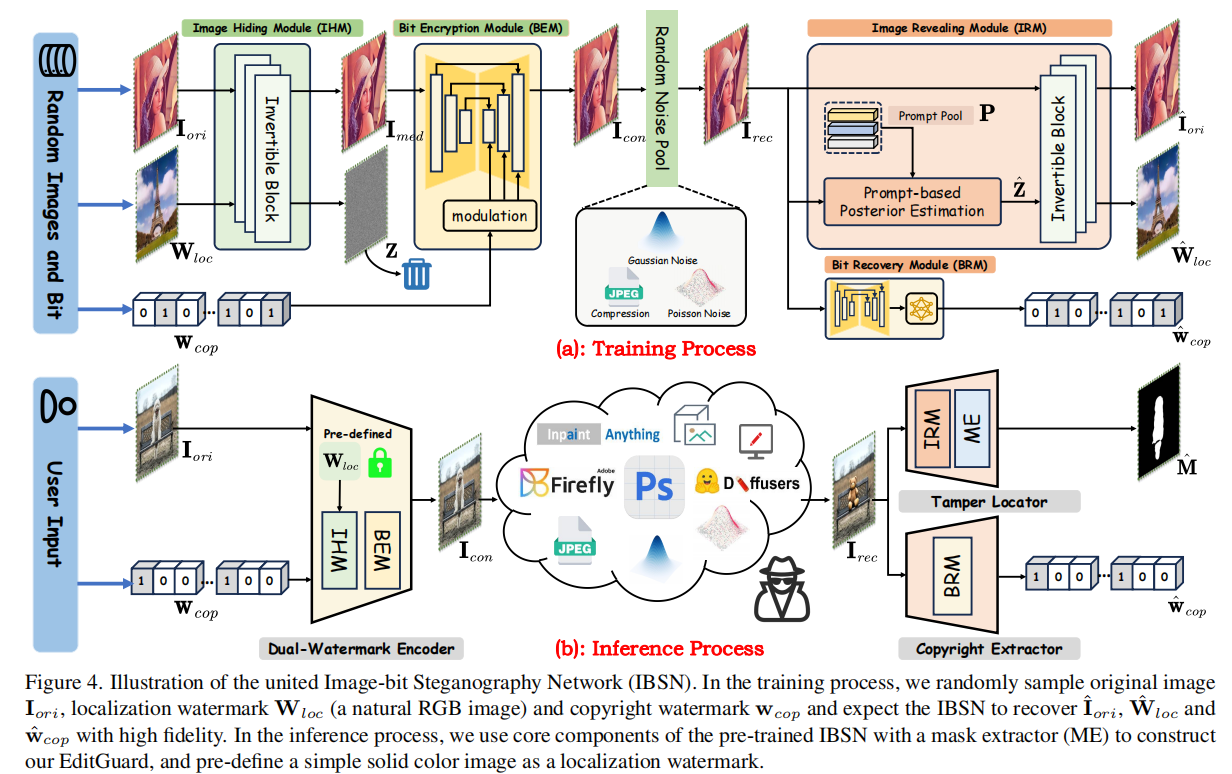
EditGuard:Versatile Image Watermarking for Tamper Localization and Copyright Protection
发表于CVPR2024,将版权水印和图像篡改主动保护两个任务联合起来。
3
UGEE-Net:Uncertainty-guided and edge-enhanced network for image splicing localization
发表于NeuralNetworks 2024。
4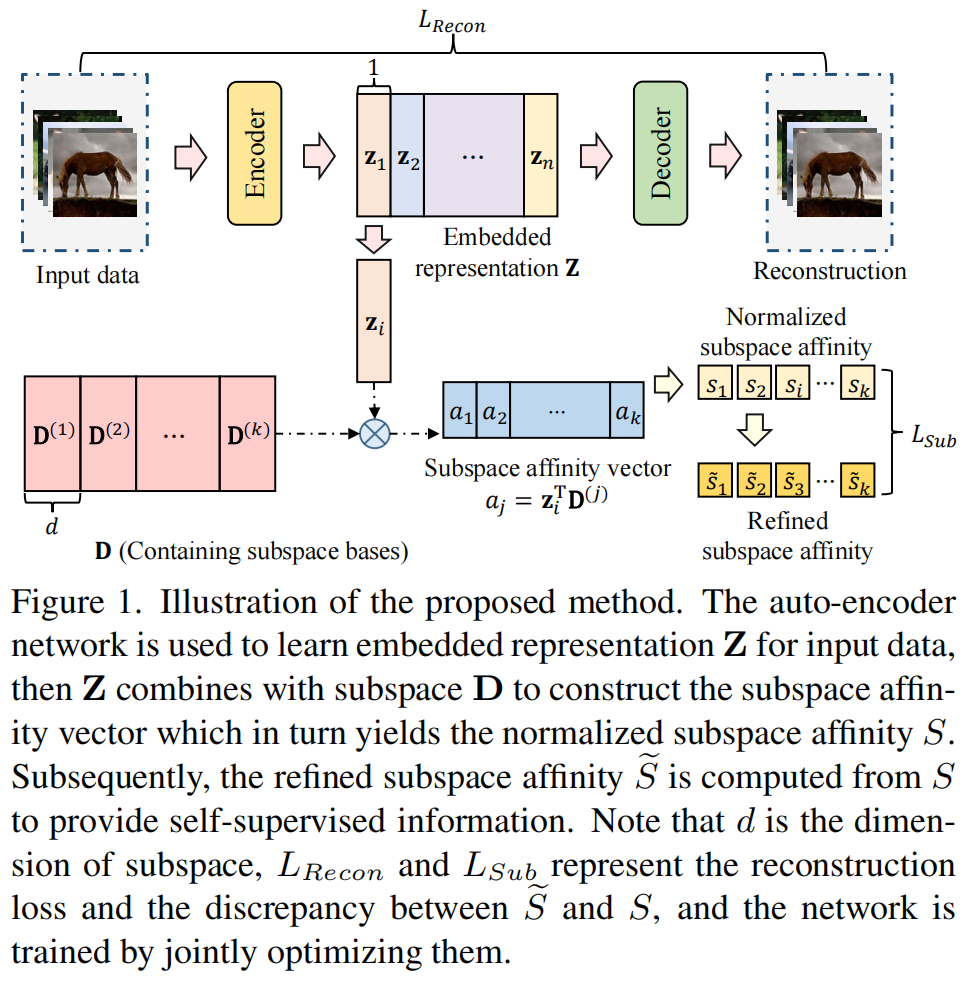
End-to-end Differentiable Clustering with Associative Memories
发表于ICML2023。
5
How to Use K-means for Big Data Clustering?
发表于Pattern Recognition 2023, 设计了一个优化kmeans的算法BigMeans。
6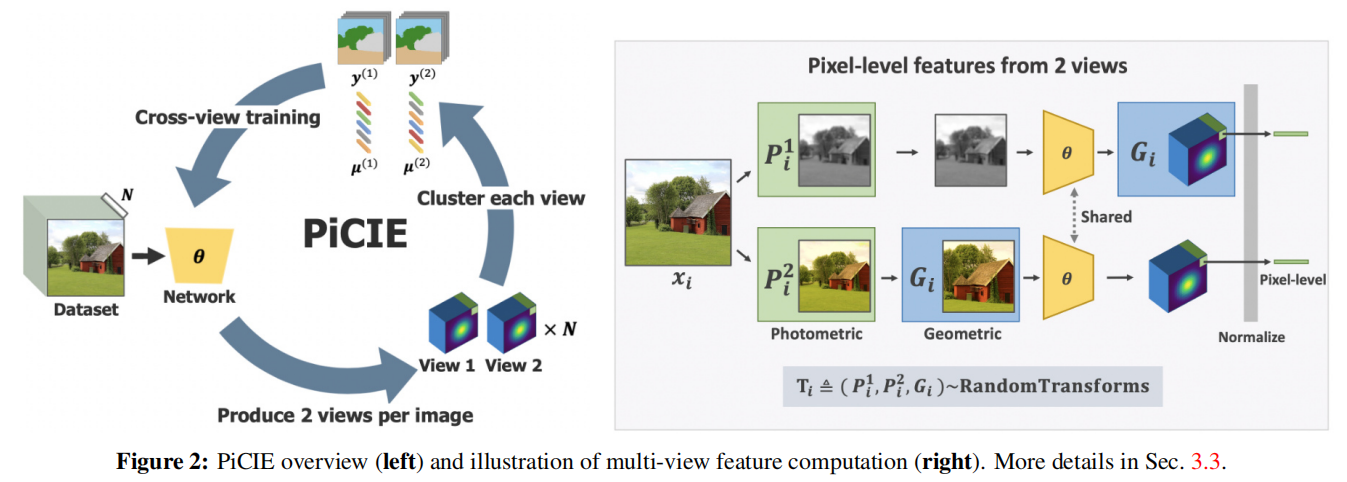
PiCIE:Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering
发表于CVPR2021,无监督语义分割,使用聚类伪标签和交叉熵损失,同时使用数据增强,利用增强不变性,提高模型泛化性,使模型不关注噪声。
7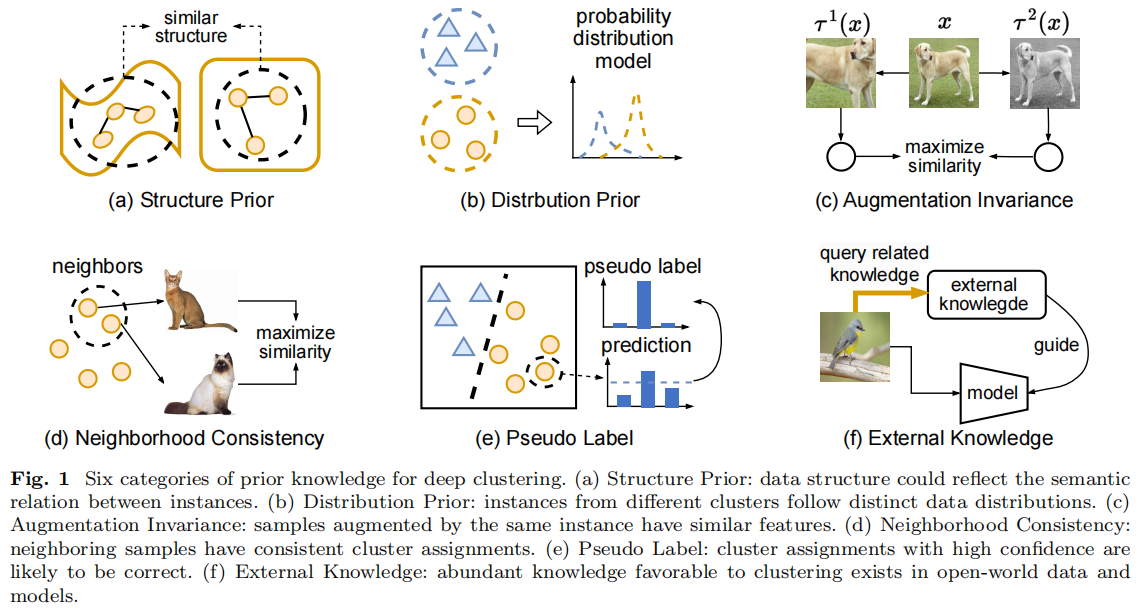
A Survey on Deep Clustering:From the Prior Perspective
发表于Vicinagearth 2024,从先验的角度看深度聚类方法,(a)结构先验:数据结构可以反映实例之间的语义关系。(b)分布先验:来自不同集群的实例遵循不同的数据分布。(c)增强不变性:由相同实例增强的样本具有相似的特征。(d)邻域一致性:相邻的样本具有一致的聚类分配。(e)伪标签:具有高可信度的聚类分配很可能是正确的。(f)外部知识:在开放世界的数据和模型中存在大量有利于聚类的知识。
8