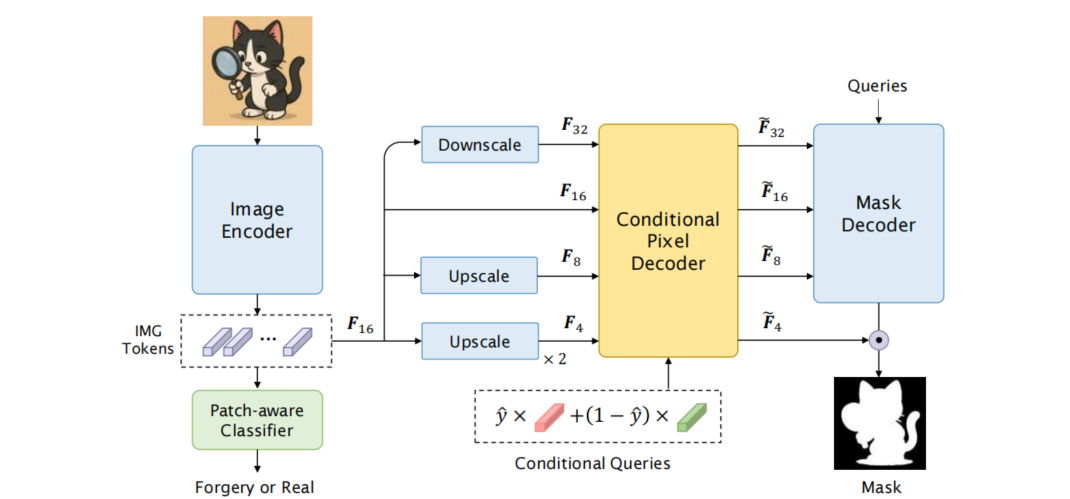
发表于IJCAI 2025,Loupe通过整合补丁感知分类器与带条件查询的分割模块,实现了全局真实性分类与细粒度掩码预测的同步处理。为增强对测试集分布偏移的鲁棒性,该模型创新性地采用伪标签引导的测试时自适应机制,利用补丁级预测结果对分割头进行监督学习。。
1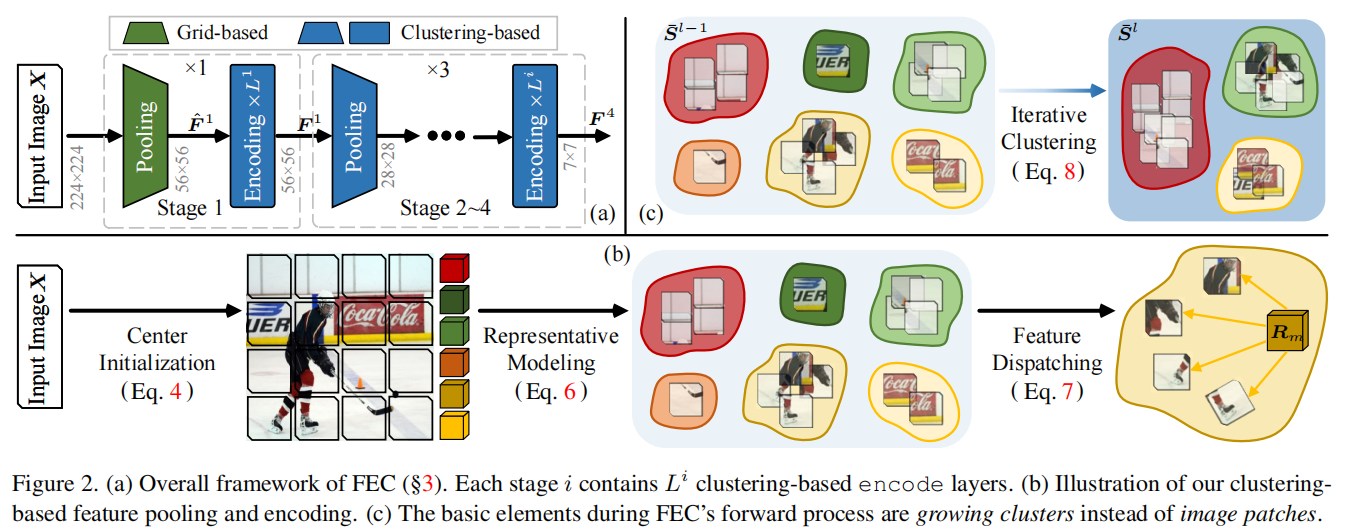
发表于CVPR2024,认为现有图像视觉提取器基于图片是平滑的这一假设设计了基于网格式的架构,因此提出了聚类特征提取FEC,在图像处理中,FEC算法通过两种交替操作实现:首先将像素分组为独立簇以提取抽象特征,随后利用当前特征向量更新像素的深度特征。这种迭代机制通过多层神经网络实现,最终生成的特征向量可直接应用于下游任务。各层间的聚类分配过程可供人工观察验证,使得FEC的前向计算过程完全透明化,并赋予其出色的自适应可解释性。
2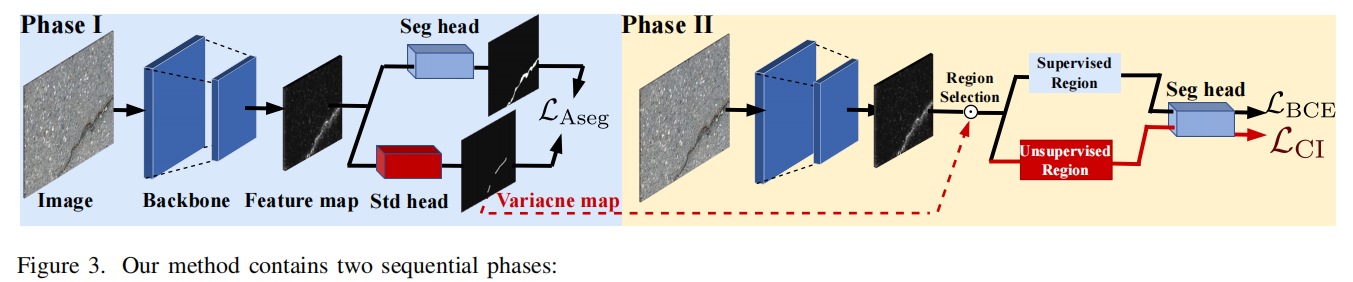
发表于CVPR2024,提出了一种基于聚类启发的表征学习框架,该框架包含自动裂缝分割的双阶段策略。第一阶段通过预处理步骤实现边缘非裂缝区域的精确定位。在第二阶段,为学习这些区域的判别性特征,我们设计了聚类启发式损失(CI Loss,*clustering-inspired loss*),将监督学习模式转变为无监督聚类方式。
3

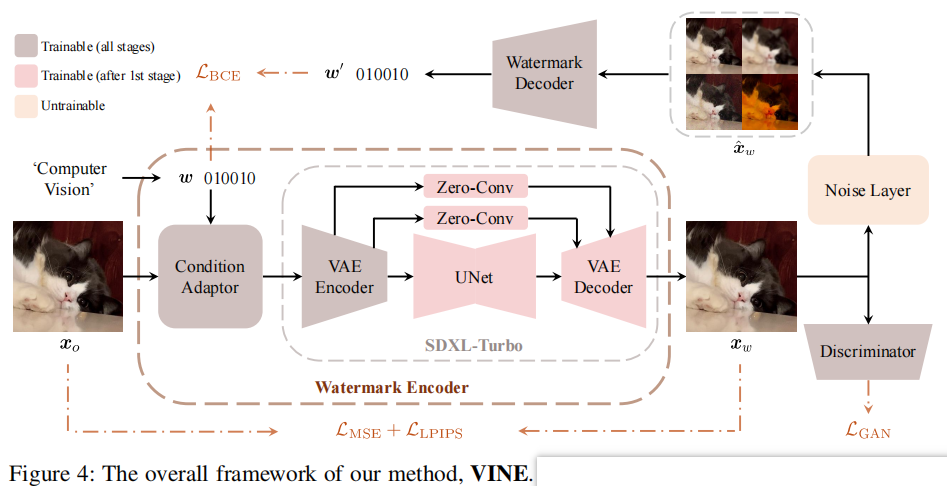
发表于ICLR2025,在本工作中,介绍了W-Bench,这是第一个全面的基准,旨在评估水印方法对广泛的图像编辑技术的鲁棒性,包括图像再生、全局编辑、局部编辑和图像到视频生成。通过实验发现图像编辑一般会消除中高频的信息,所以需要将水印信息保存在低频中
7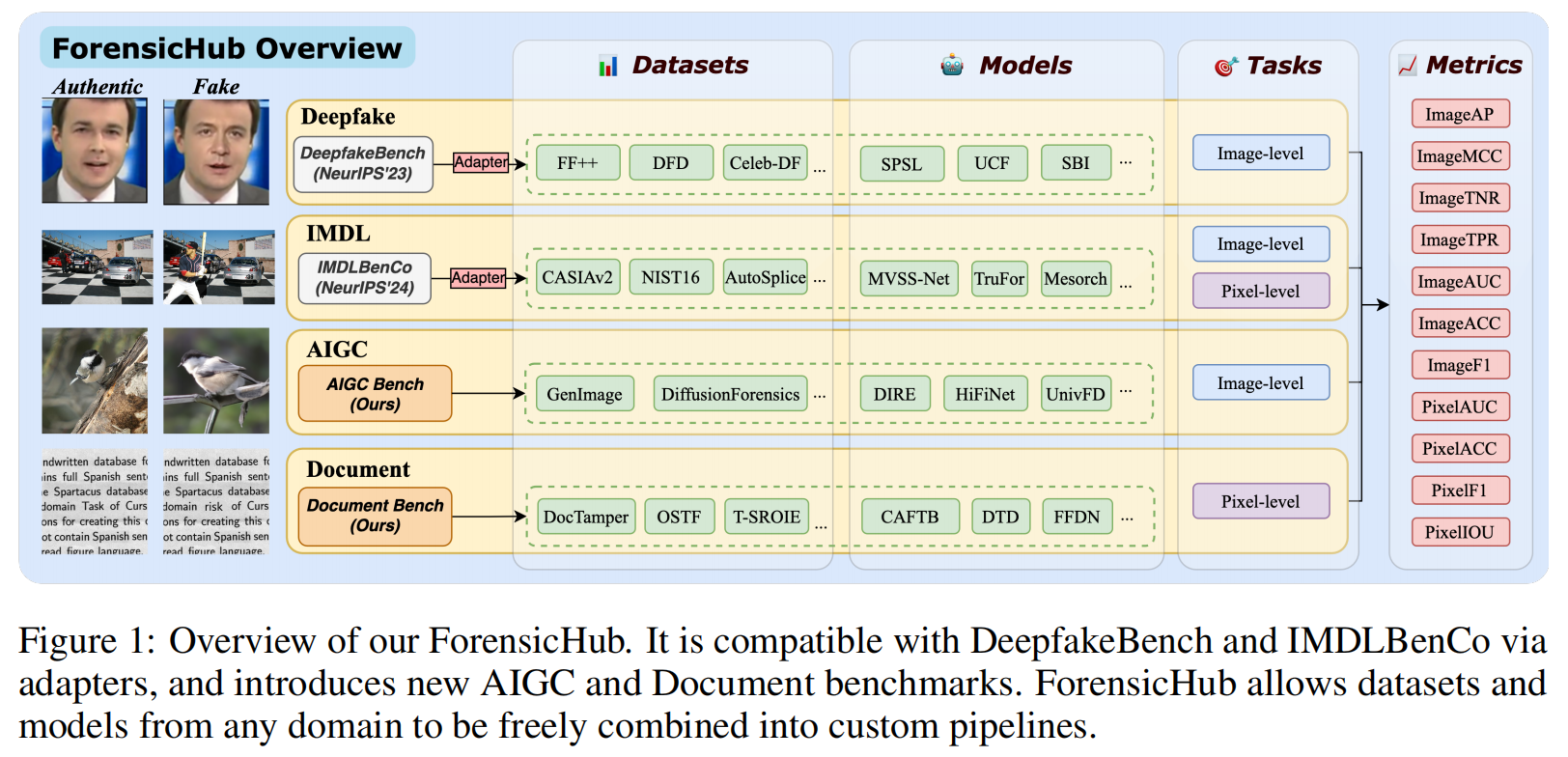
发表于arxiv上的论文,非常棒的工作!其整合了深度伪造检测、图像篡改检测/定位、AI生成图像检测和文档图像处理定位四大任务,并基于基准实验,提出了独特的发现。
8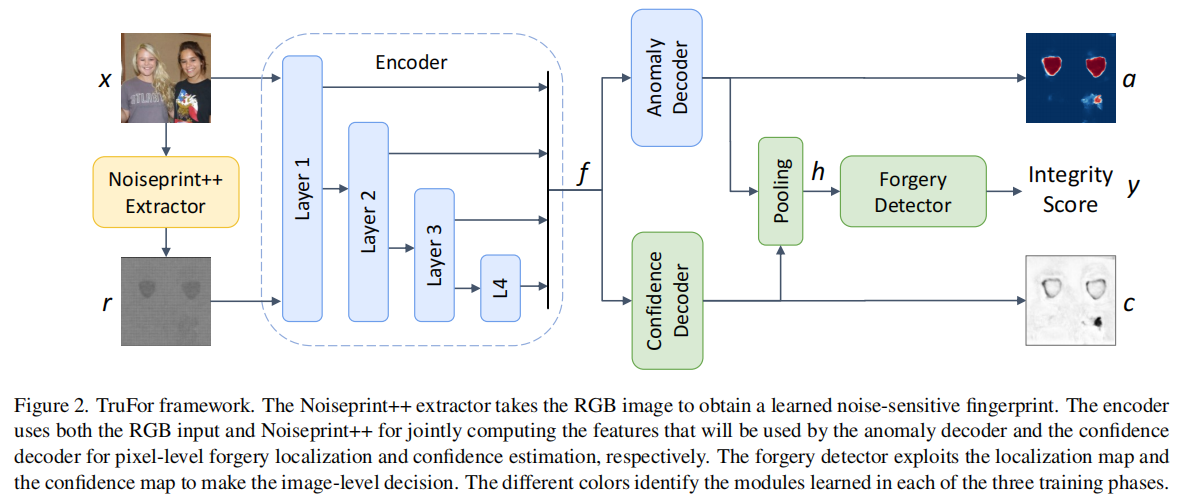
发表于CVPR2023,该框架通过基于Transformer的融合架构,同时提取高阶特征与低阶特征:前者整合RGB图像与自适应学习的噪声敏感指纹,后者则通过仅使用真实数据进行自监督训练,精准捕捉相机内外部处理产生的伪影特征。
9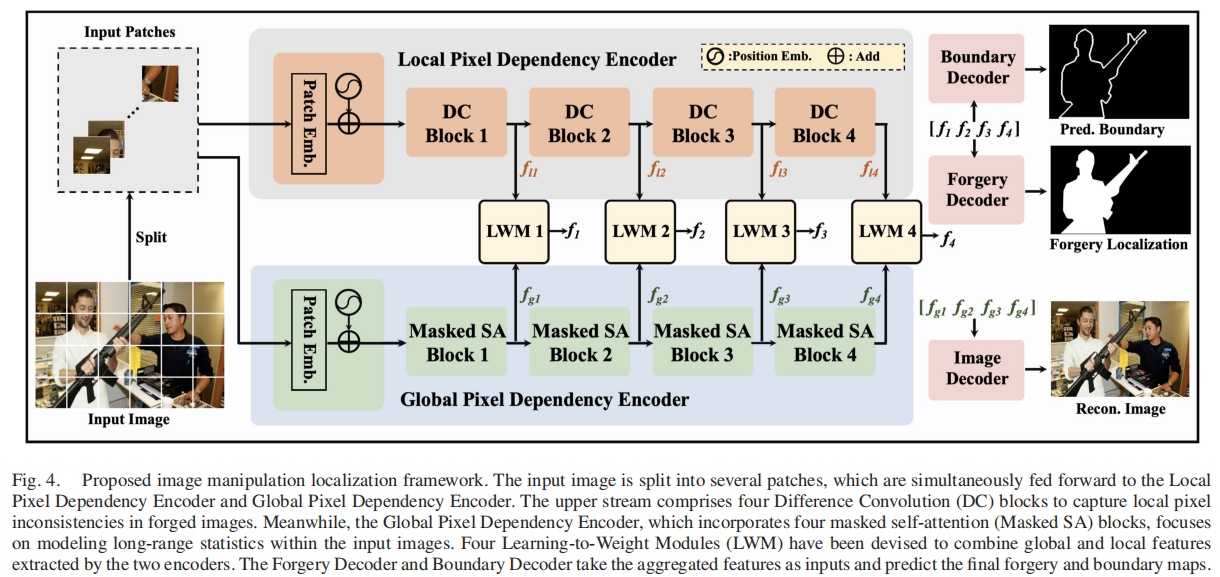
发表于TPAMI2025,将输入图像分割成多个区块后,分别使用掩码自注意力和差异卷积分别建模全局和局部像素依赖,同时设计了新型的学习加权模块来融合全局和局部的特征,还设计了像素不一致性数据增强方法增强鲁棒性。但其比较论文实验的结果和原本论文在相同数据集相同指标下的结果相差太多,之后尝试在已给代码上进行测试,再完成之后阅读。
10