文章总览 - 191

Efficient_Video_Integrity_Analysis_Through_Container_Characterization
31
Video_Source_Characterization_Using_Encoding_and_Encapsulation_Characteristics
32
container
33Fusion_Transformer_with_Object_Mask_Guidance_for_Image_Forgery_Analysis
34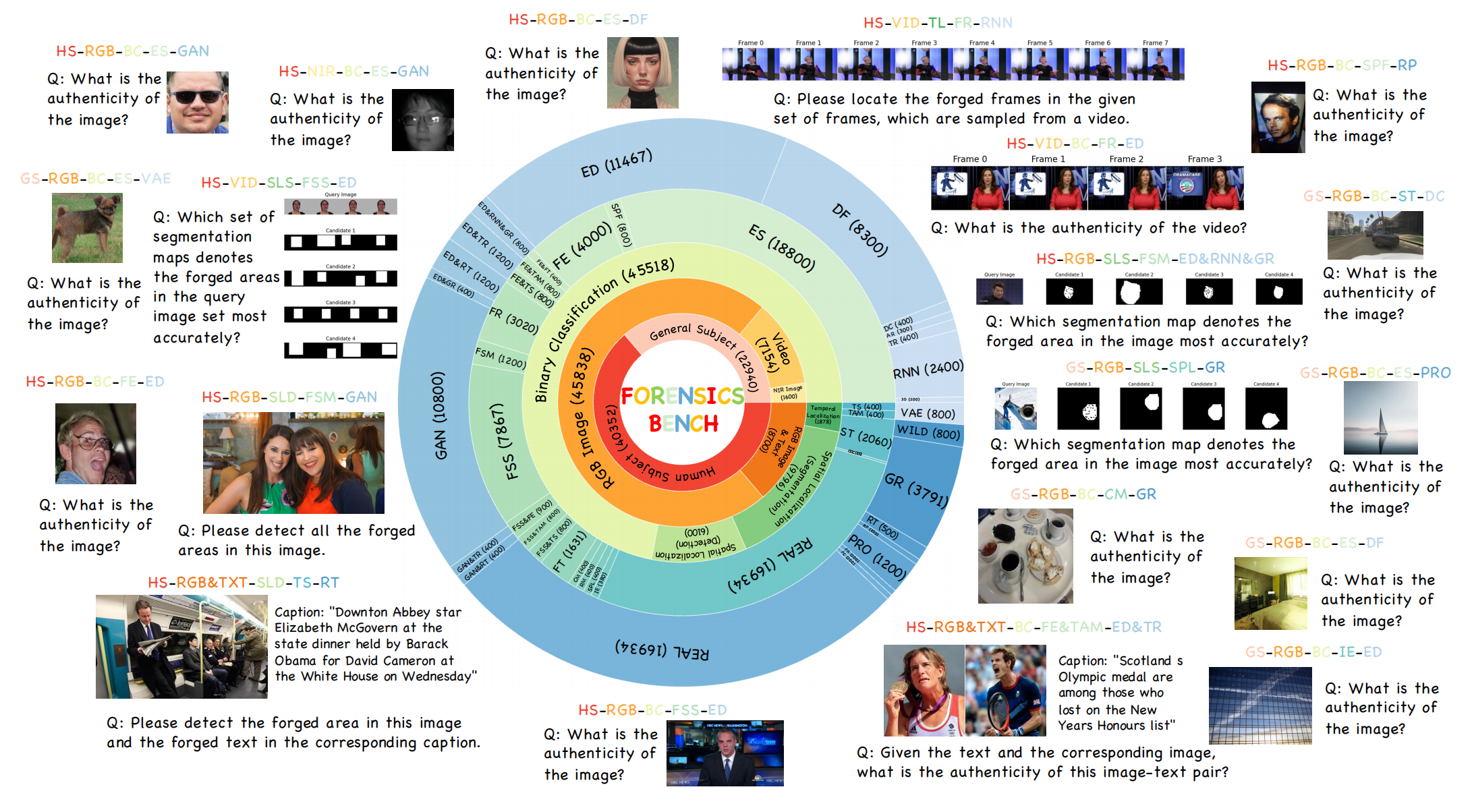
Forensics-Bench:A Comprehensive Forgery Detection Benchmark Suite for Large Vision Language Models
发表于CVPR2025,提出了Forensics-Bench,统一了所有基于大型视觉语言模型LVLMs的伪造检测器,并基于基准实验,提出了独特的发现。
35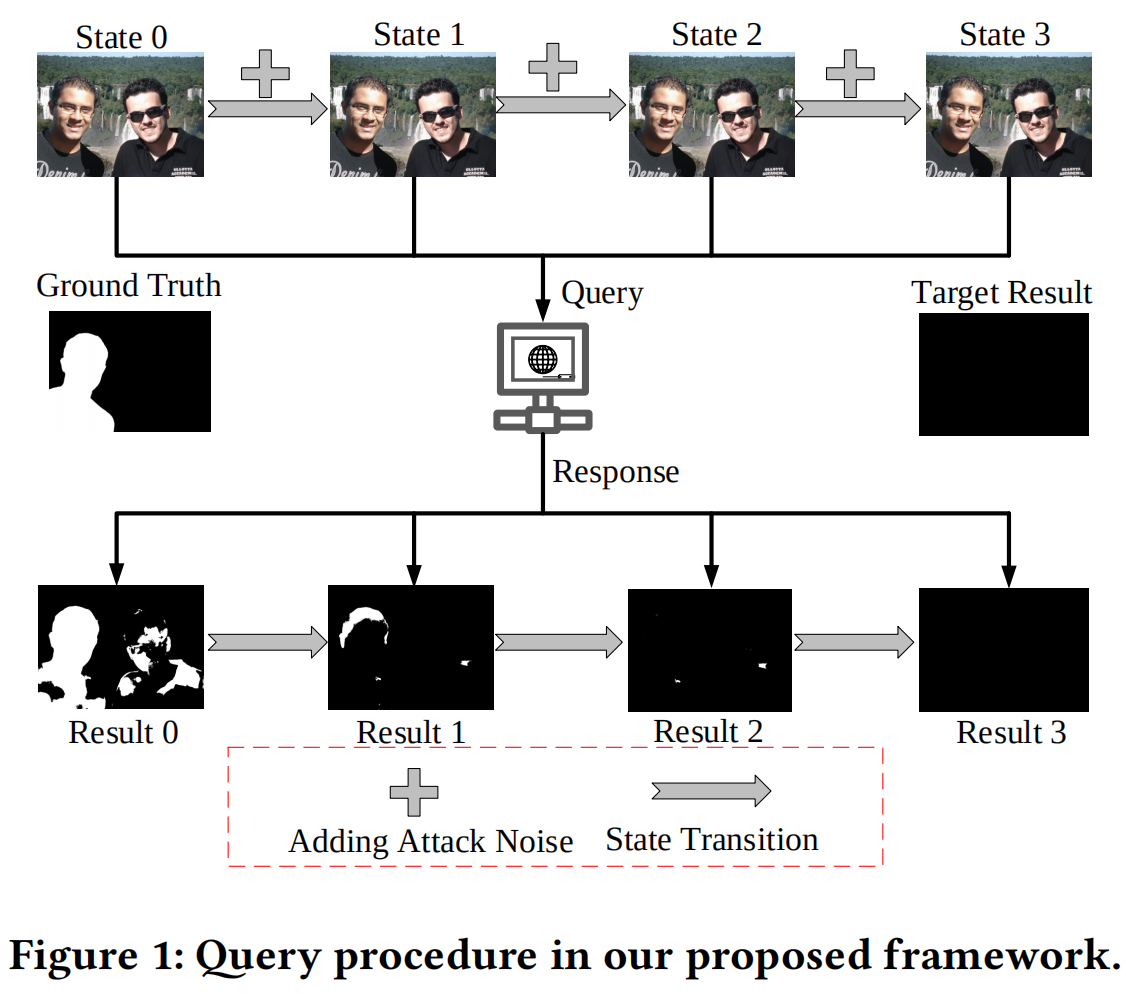
Poster:Query-efficient Black-box Attack for Image Forgery Localization via Reinforcement Learning
发表于CVPR2022。
36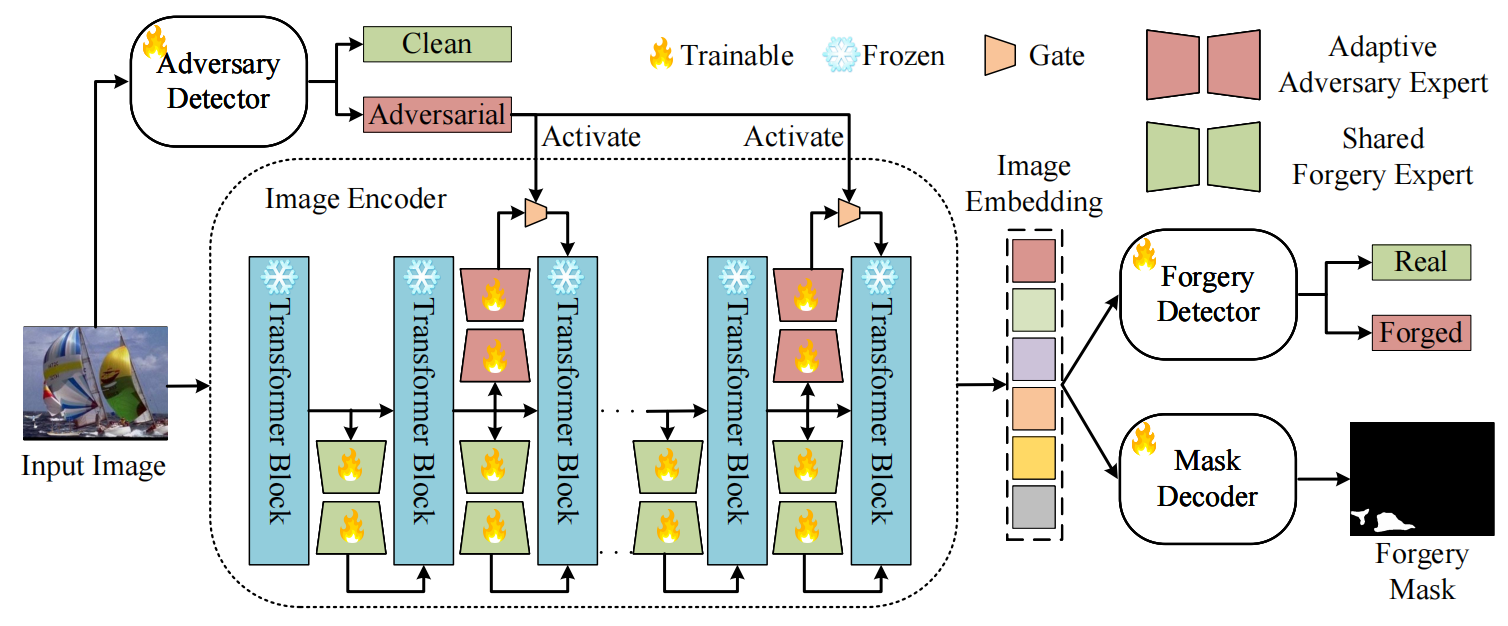
ForensicsSAM
发表于aixiv。
37aggregate_multi_scale
这篇写聚合多尺度特征或者多尺度预测的方法。
38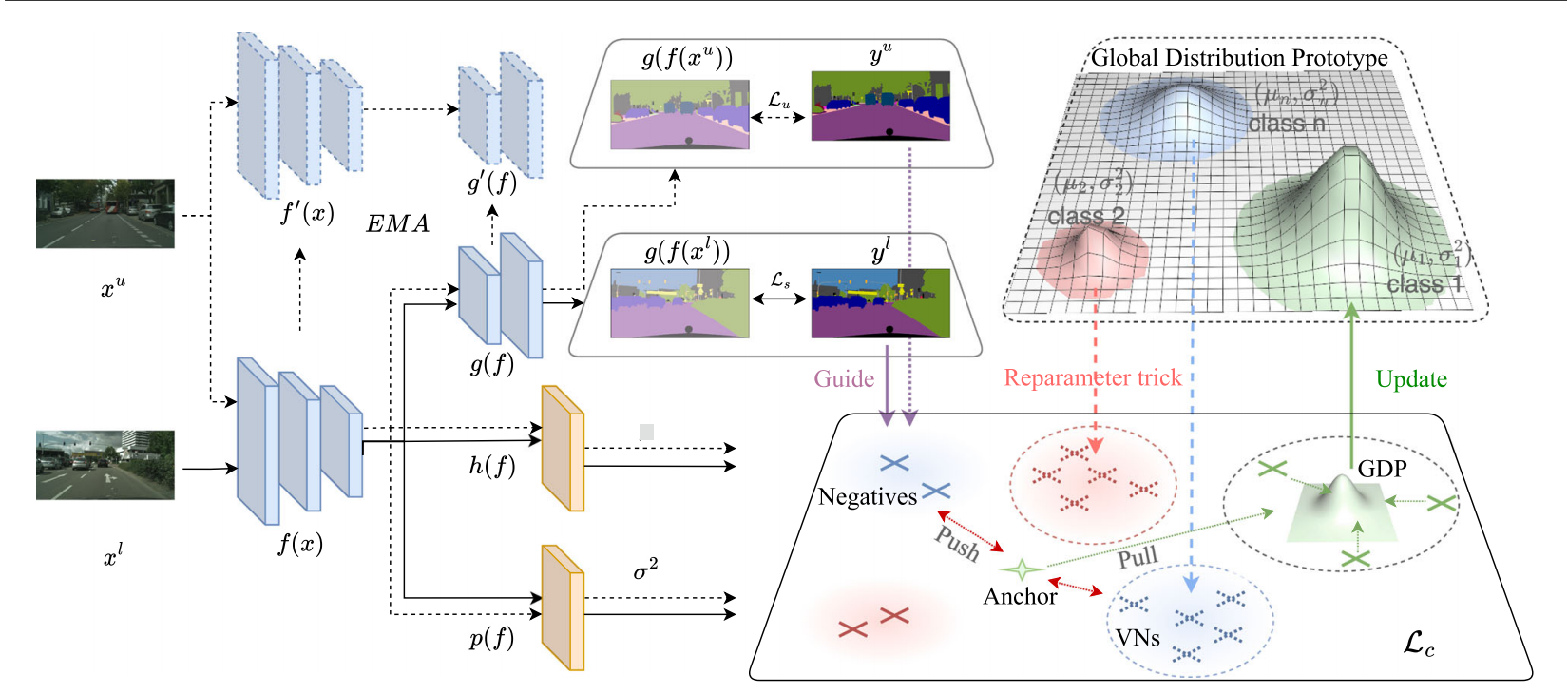
PRCL:Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation
发表于IJCV2024,同时是AAAI 2023的oral,将对比学习引入到师生网络,本文提出使用多元高斯分布将像素级表示建模为概率表示(PR)。PR包含一个捕获最可能表示的均值向量和一个表示可靠性的方差向量。PR之间的相似性是通过相互似然评分来衡量的,该评分减少了不确定表示的影响。对于第二个问题,引入了全球分布原型(GDP),以在整个训练过程中聚合全球表示,确保原型位置的一致性。此外,虚拟负片可以从GDP中有效地生成,以补偿零碎的负分布,而不需要内存库。。
39Region-aware_Contrastive_Learning_for_Semantic_Segmentation
40