文章总览 - 191

CoOp:Learning to Prompt for Vision-Language Models
61CLIP:Learning Transferable Visual Models From Natural Language Supervision
62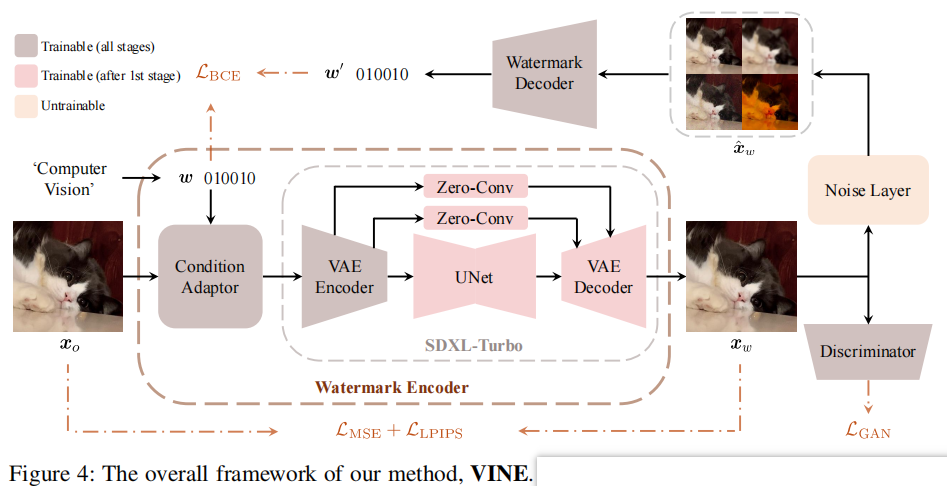
Robust Watermarking Using Generative Priors Against Image Editing:From Benchmarking to Advances
发表于ICLR2025,在本工作中,介绍了W-Bench,这是第一个全面的基准,旨在评估水印方法对广泛的图像编辑技术的鲁棒性,包括图像再生、全局编辑、局部编辑和图像到视频生成。通过实验发现图像编辑一般会消除中高频的信息,所以需要将水印信息保存在低频中
63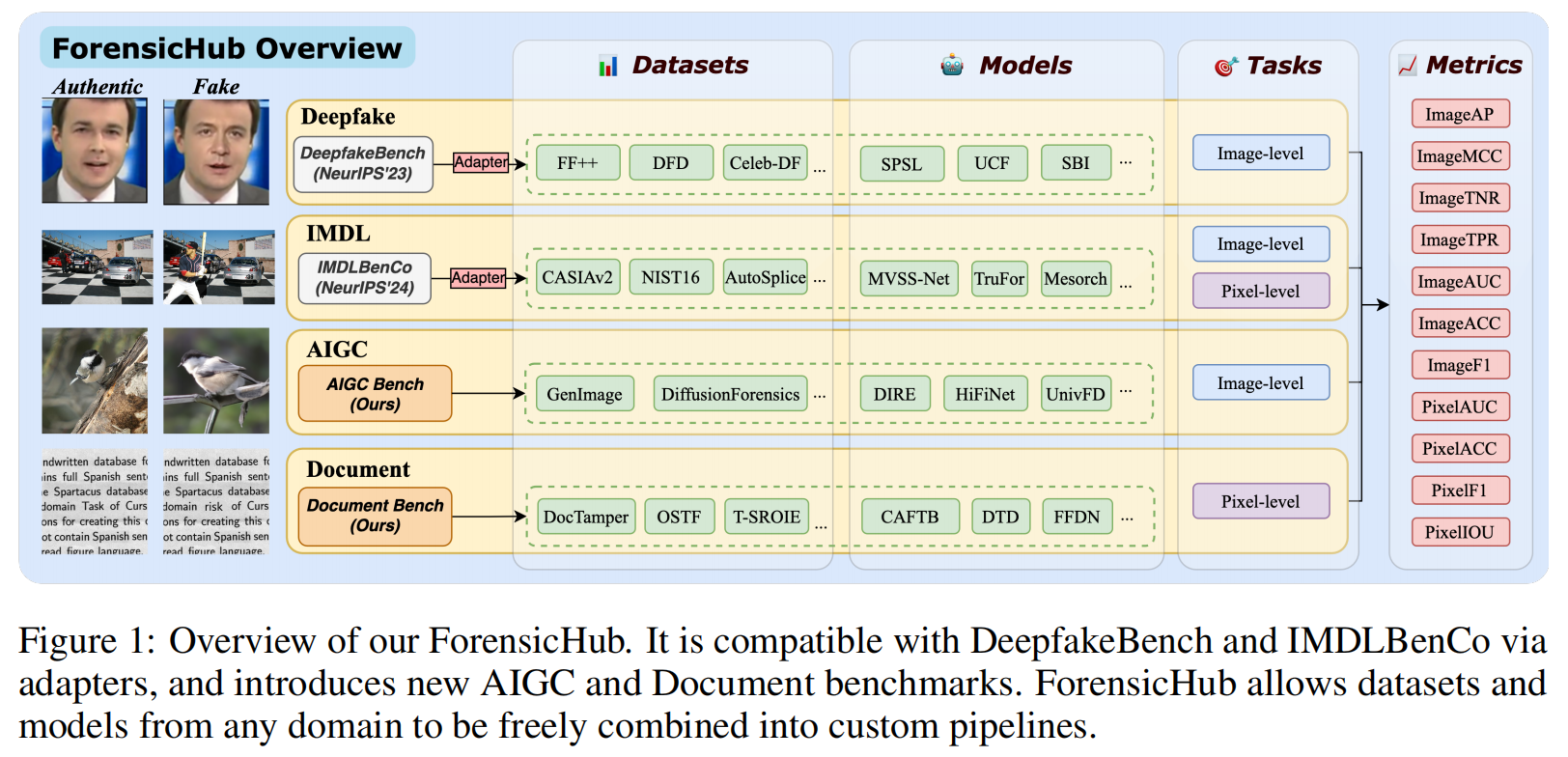
ForensicHub:A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization
发表于arxiv上的论文,非常棒的工作!其整合了深度伪造检测、图像篡改检测/定位、AI生成图像检测和文档图像处理定位四大任务,并基于基准实验,提出了独特的发现。
64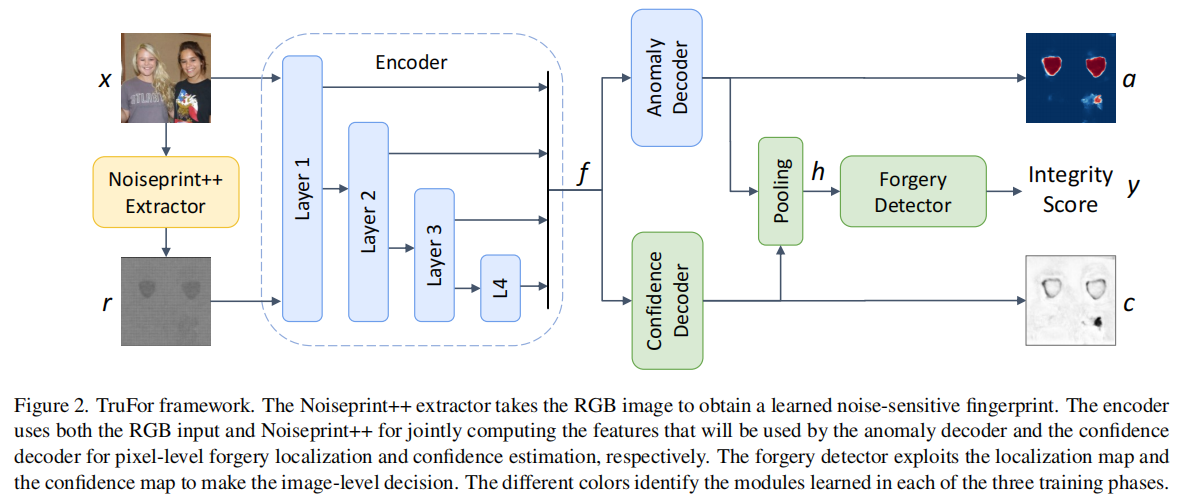
TruFor:Leveraging all-round clues for trustworthy image forgery detection and localization
发表于CVPR2023,该框架通过基于Transformer的融合架构,同时提取高阶特征与低阶特征:前者整合RGB图像与自适应学习的噪声敏感指纹,后者则通过仅使用真实数据进行自监督训练,精准捕捉相机内外部处理产生的伪影特征。
65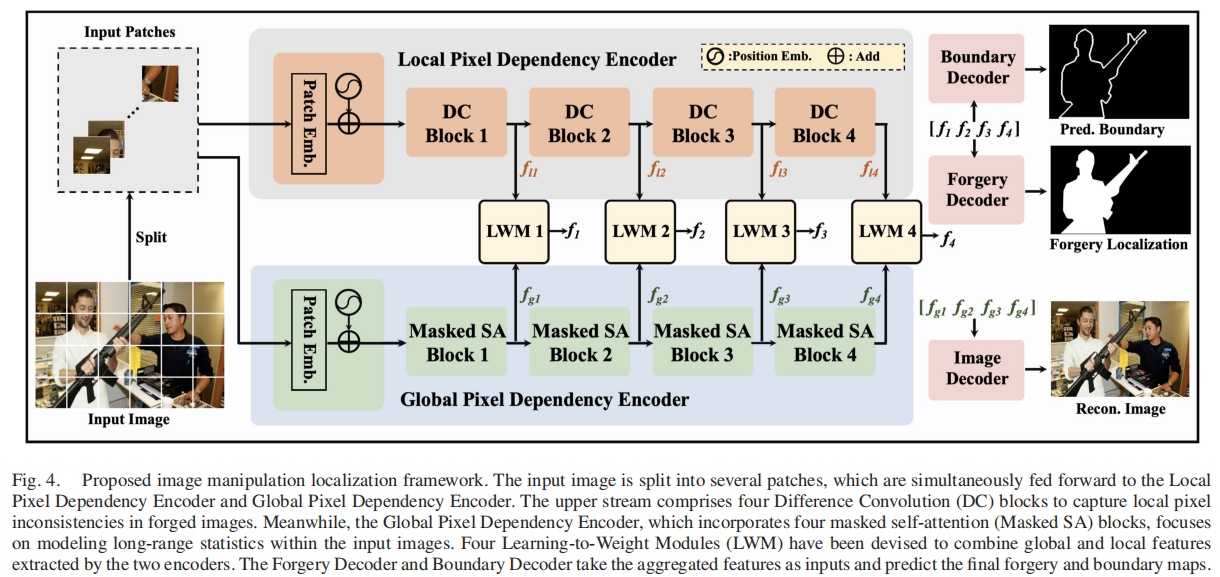
Pixel-Inconsistency Modeling for Image Manipulation Localization
发表于TPAMI2025,将输入图像分割成多个区块后,分别使用掩码自注意力和差异卷积分别建模全局和局部像素依赖,同时设计了新型的学习加权模块来融合全局和局部的特征,还设计了像素不一致性数据增强方法增强鲁棒性。但其比较论文实验的结果和原本论文在相同数据集相同指标下的结果相差太多,之后尝试在已给代码上进行测试,再完成之后阅读。
66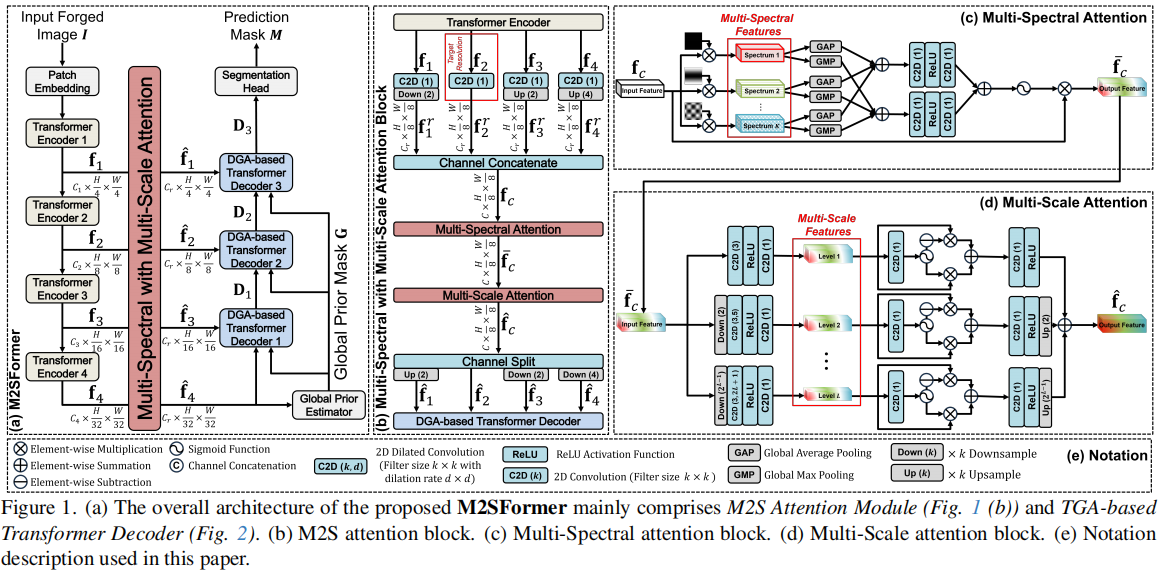
M2SFormer:Multi-Spectral and Multi-Scale Attention with Edge-Aware Difficulty Guidance for Image Forgery Localization
发表于ICCV2025,拿到了Highlight,M2SFormer通过在跳跃连接中统一多频段和多尺度注意力机制,借助全局上下文信息,能更精准捕捉各类伪造特征。此外,框架通过采用全局先验图(一种反映伪造检测难度的曲率度量指标)来解决上采样过程中细节丢失的问题。该方法使用分割的指标而不是图像篡改的传统指标,而且比较的方法并不是公认的sota。
67
ImgEdit
68
Knowledge_Distillation
69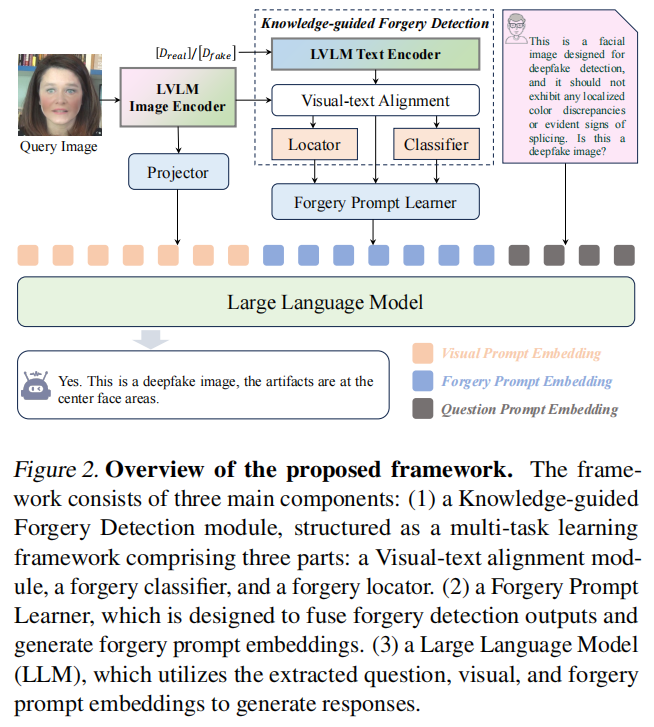
Unlocking the Capabilities of Large Vision-Language Models for Generalizable and Explainable Deepfake Detection
发表于ICML2025,将细粒度的伪造特征转化为语言模型的输入,在LLM提示调优后,得到解释性的deepfake检测结果。
70