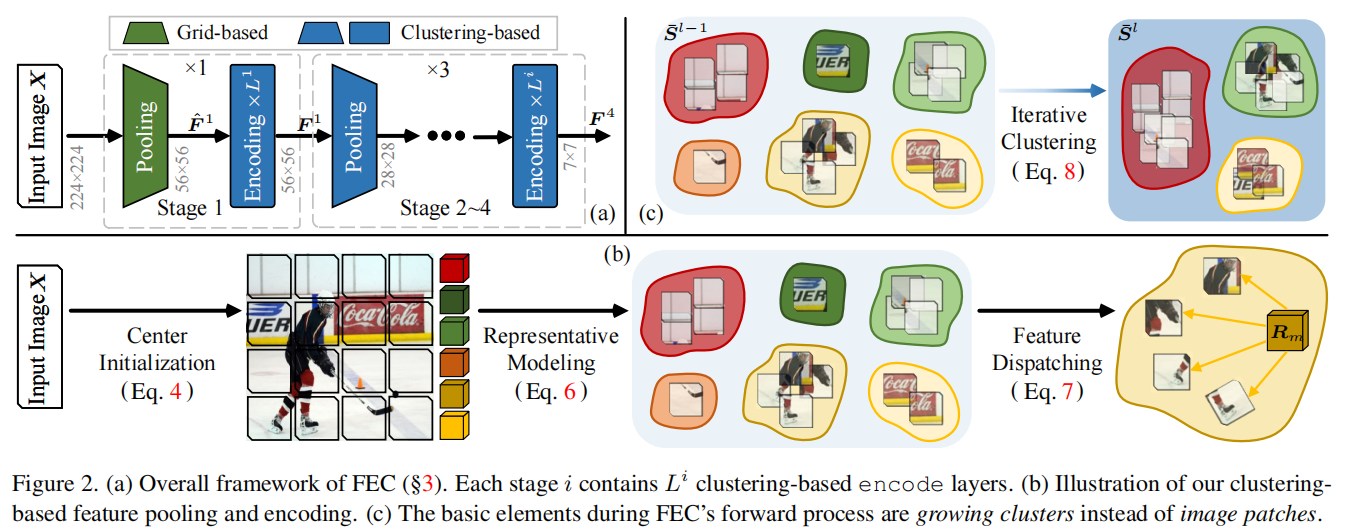
发表于CVPR2024,认为现有图像视觉提取器基于图片是平滑的这一假设设计了基于网格式的架构,因此提出了聚类特征提取FEC,在图像处理中,FEC算法通过两种交替操作实现:首先将像素分组为独立簇以提取抽象特征,随后利用当前特征向量更新像素的深度特征。这种迭代机制通过多层神经网络实现,最终生成的特征向量可直接应用于下游任务。各层间的聚类分配过程可供人工观察验证,使得FEC的前向计算过程完全透明化,并赋予其出色的自适应可解释性。
1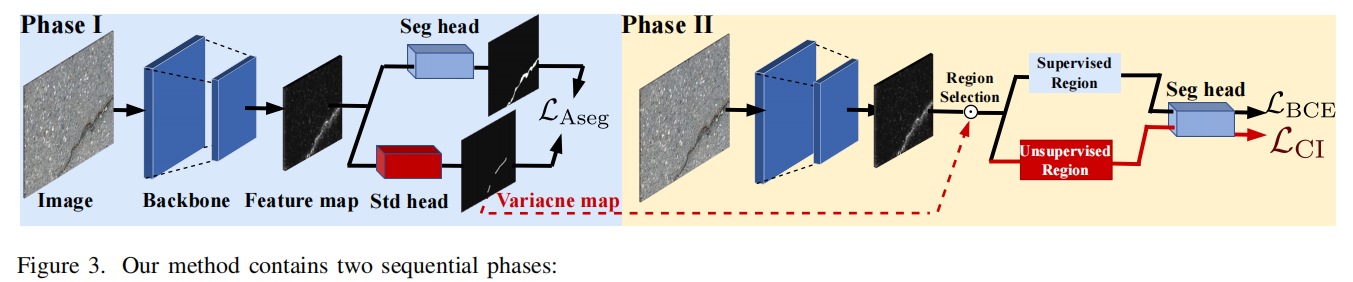
发表于CVPR2024,提出了一种基于聚类启发的表征学习框架,该框架包含自动裂缝分割的双阶段策略。第一阶段通过预处理步骤实现边缘非裂缝区域的精确定位。在第二阶段,为学习这些区域的判别性特征,我们设计了聚类启发式损失(CI Loss,*clustering-inspired loss*),将监督学习模式转变为无监督聚类方式。
2
发表于CVPR2024,提出了一种新的无监督域适应方法,该方法采用聚类三元组损失函数,仅使用源域中的少量信息,从而提升目标域的性能。以源域中的重要节点的聚类中心为锚点,通过三元组损失,将目标域锚定到这些固定的聚类中心。源域的完美结构应该与目标域的完美结构相似,才能用作锚点。
3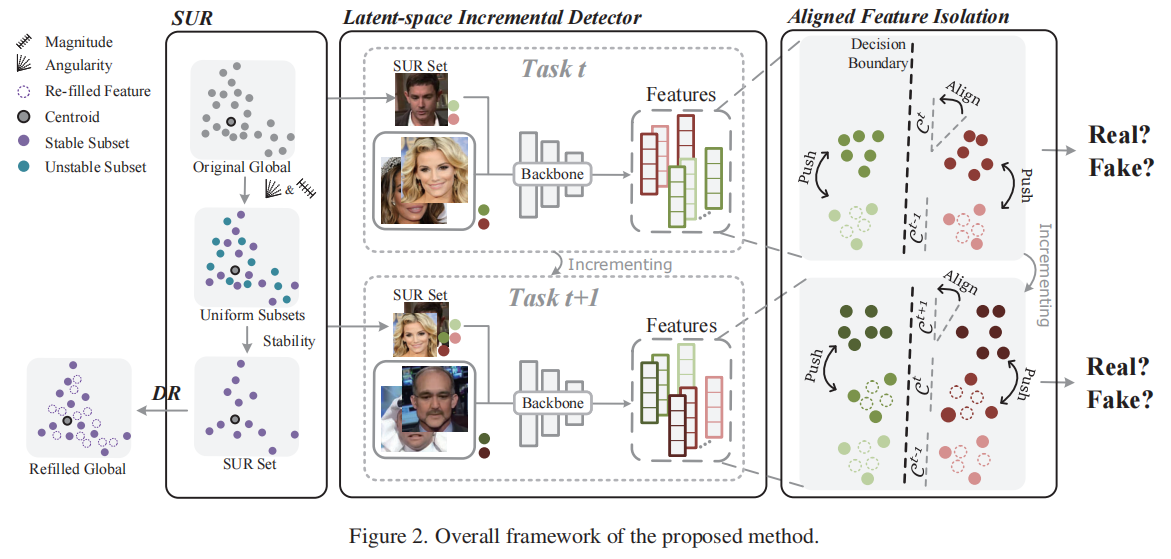
发表于CVPR2025,一个未经充分训练的IFFD模型在处理新的伪造时容易出现灾难性遗忘,这是因为将所有伪造都视为单一的“假”类别,导致不同类型的伪造品相互覆盖,从而导致早期任务中独特特征的遗忘,这存在于所有的IDF任务中,该论文提出了一种方法,通过将先前任务和新任务的潜在特征分布逐块堆叠,实现特征的对齐隔离。为了保留已学习到的伪造信息,并通过最小化分布重叠来积累新知识,从而减轻灾难性遗忘。首先引入了稀疏均匀回放(SUR),以获取可以视为先前全局分布的均匀稀疏版本的代表性子集。接着,我们提出了一个潜在空间增量检测器(LID),该检测器利用SUR数据来隔离和对齐分布。
4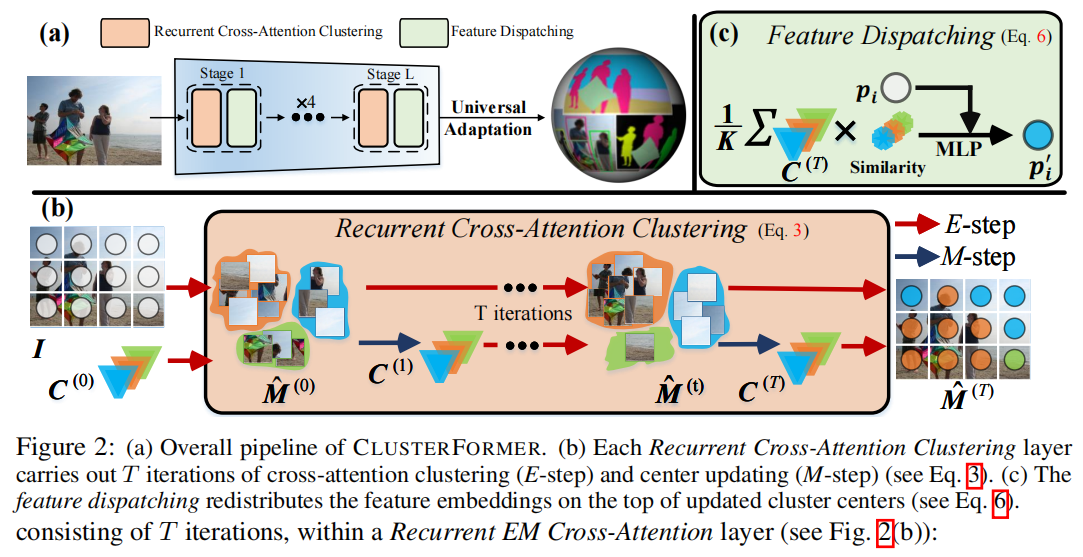
发表于NeurIPS2023,本文介绍了一种基于CLUSTERing范式与TransFORMER的通用视觉模型——CLUSTERFORMER。该模型包含两个创新设计:①循环交叉注意力聚类,重新定义了TransFORMER中的交叉注意力机制,通过递归更新聚类中心,促进强大的表示学习;②特征调度,利用更新后的聚类中心,通过基于相似性的度量重新分配图像特征,形成一个透明的处理流程。
5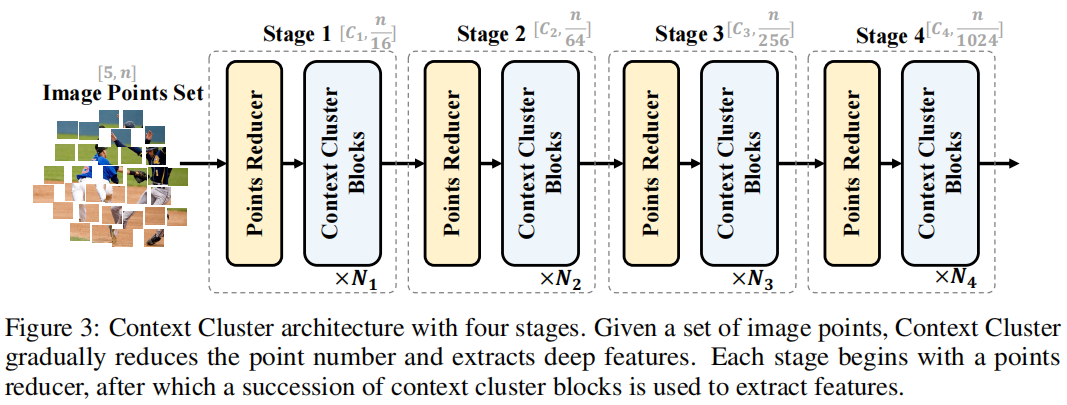
发表于ICLR2023,将图像视为一组无组织的点,并通过简化的聚类算法提取特征。具体地说,每个点都包括原始特征(如颜色)和位置信息(如坐标),并采用简化的聚类算法对深度特征进行分层分组和提取。
6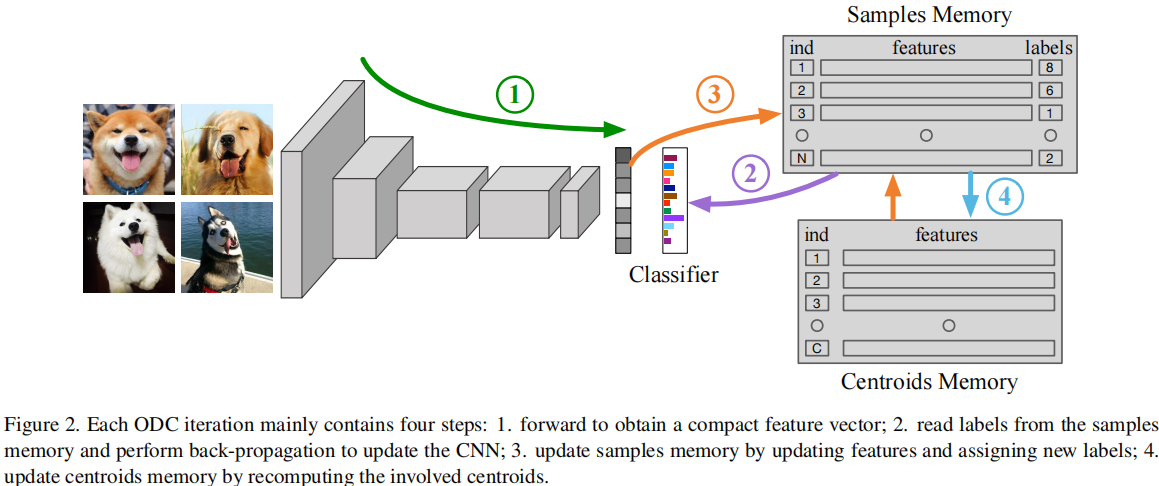
发表于CVPR2020,其提出了在线深度聚类的方法,即设计并维护了两个动态内存模块,即用于存储样本标签和特征的样本内存,以及用于质心进化的质心内存,将突然的全局聚类分解为稳定的内存更新和批量标签重新分配。
7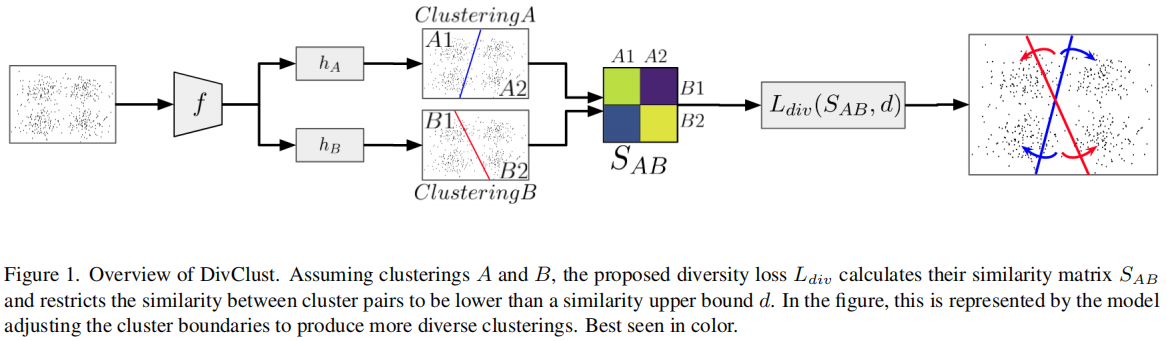
发表于CVPR2023,共识聚类是一种无监督的集成聚类方法,旨在通过多次重采样和聚类分析来评估聚类结果的稳定性,从而确定数据集中最优的聚类数目(k值)及其成员结构。该论文提出了DivClust,一种多样性控制损失,可以纳入现有的深度聚类框架,以产生具有所需多样性程度的多个聚类。
8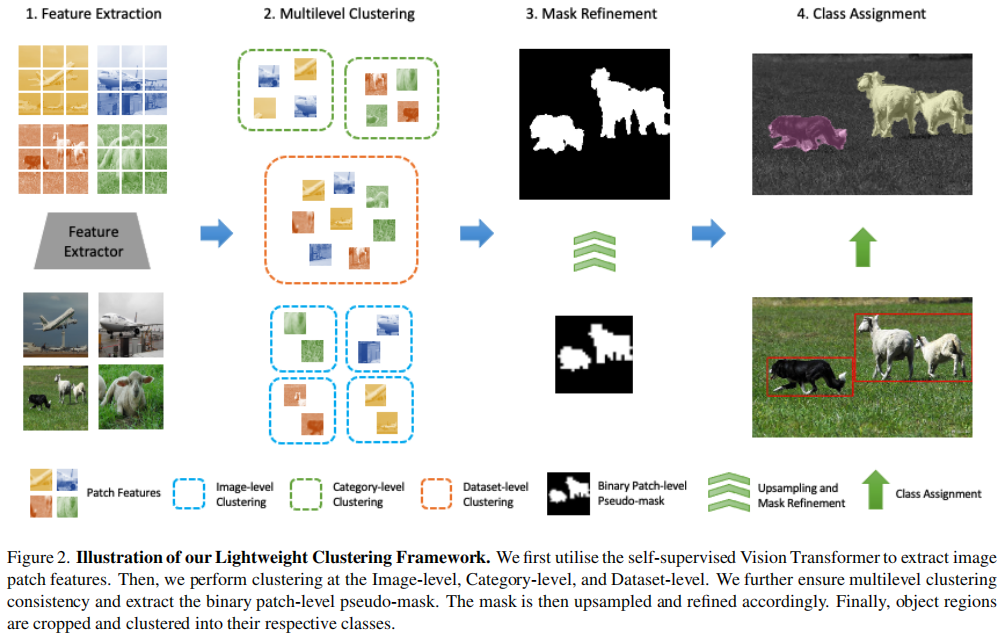
aixiv文章,面对无监督语义分割,使用多级聚类的方法来实现。
9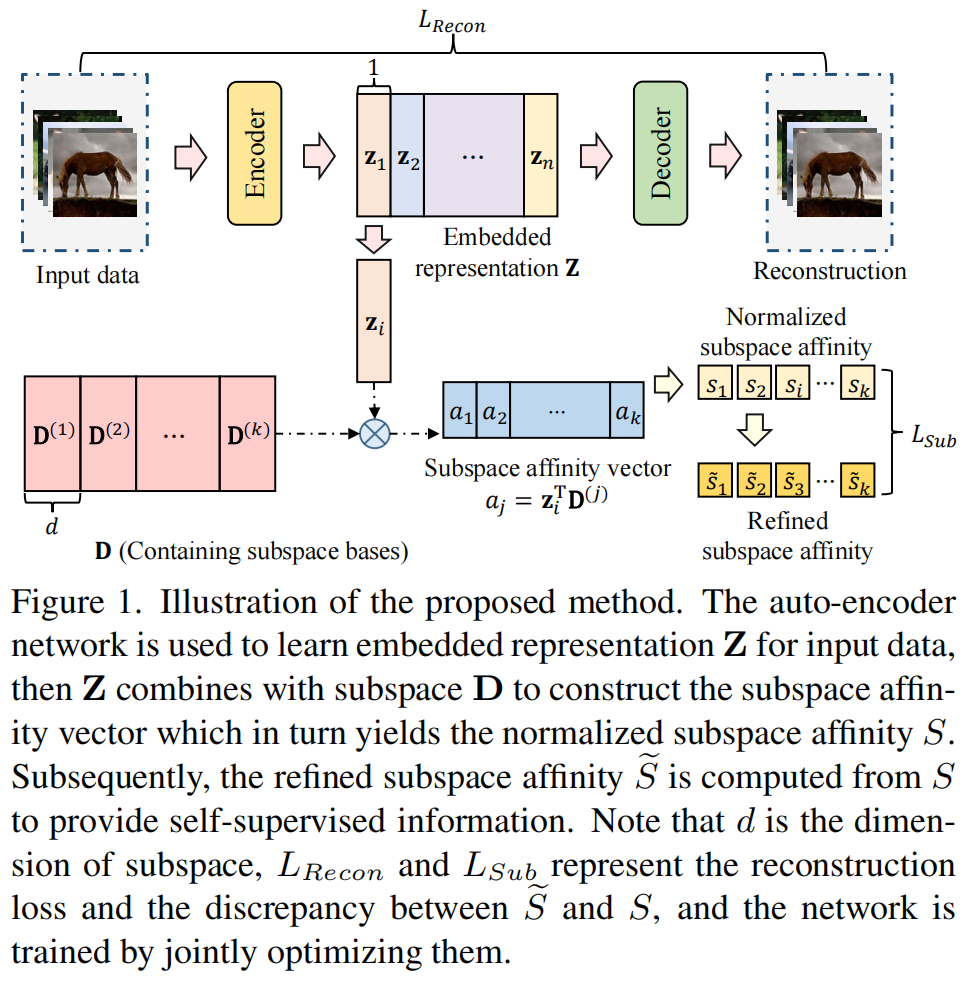
发表于ICML2023。
10