MGQFormer: Mask-Guided Query-Based Transformer for Image Manipulation Localization
发表于AAAI2024,为应对交叉熵损失优先考虑逐像素精度,但忽略了篡改区域的空间位置和形状细节,设计了基于掩码引导查询的转换器框架(MGQFormer),该框架使用GroundTruth掩码来引导可学习查询令牌(LQT)识别伪造区域。
*现有问题*: - 所有现有的IMD主要通过交叉熵损失使用真值掩码,该损失优先考虑逐像素精度,但忽略了篡改区域的空间位置和形状细节。
*解决方案*:一种基于掩码引导查询的转换器框架(MGQFormer),该框架使用基本事实掩码来引导可学习查询令牌(LQT)识别伪造区域。
具体情况
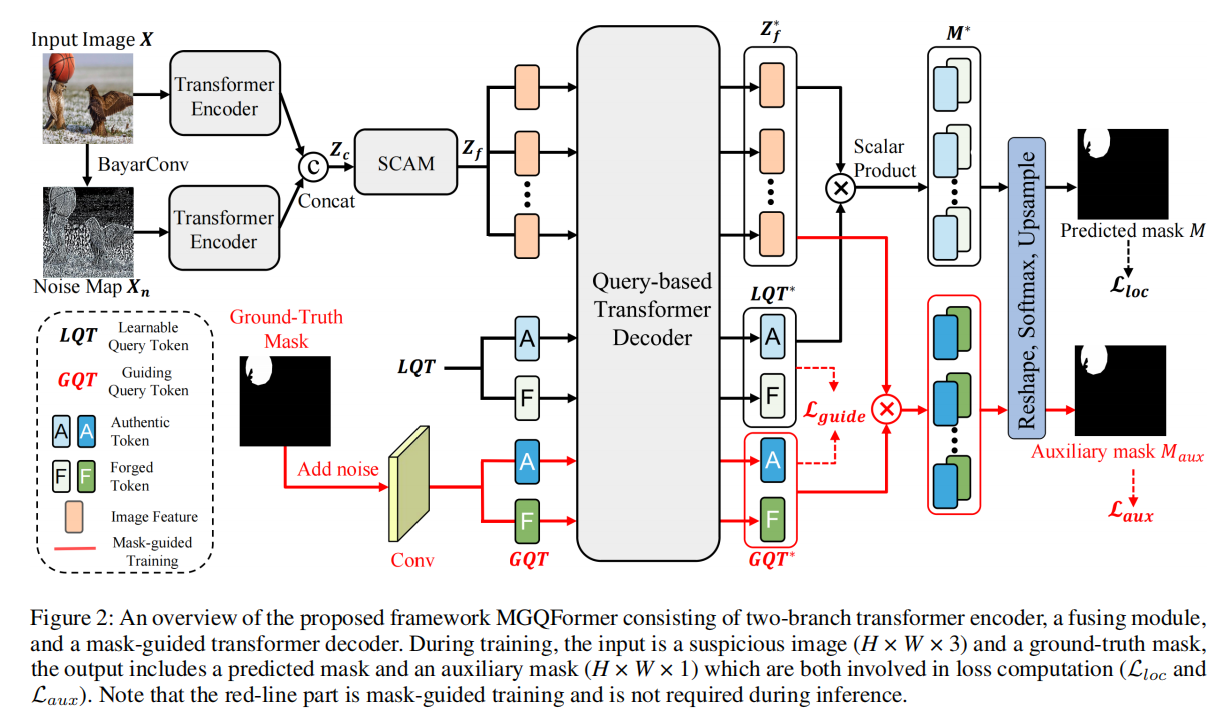
利用BayarConv和Transformer编码器从输入图像中提取RGB和噪声特征,过空间和通道注意模块(SCAM,spatial and channel attention module)对多模态特征进行融合。其特征提取器如下:
 我们设计了两个可学习的查询token来表示真实和伪造的特征,它们用于在我们提出的基于查询的Transformer解码器中搜索篡改区域。为了使查询token有效参考和基于查询的解码器快速收敛,我们提出了一种利用GroundTruth掩模的空间位置和形状细节的掩模引导训练策略。其解码器如下:

具体来说,我们将噪声的GT掩模输入MGQFrorer,以获得引导查询token(GQT)和辅助掩模 $ M_{aux} $ 。然后,利用辅助损失 $ L_{aux} $ ,使GQT包含伪造区域的空间和形状信息。此外,我们提出了一种掩模引导的损失 $ L_{guide} $ 来减小LQT和GQT之间的距离。
1